Digital Image Processing
数字图像处理课程作业
图像的几何变换
1.图像放大缩小
-
描述:设一幅大小为$M \times N$的灰度图像$I$中,现要将其尺寸调整至大小为$P \times Q$的图像$J$
- 算法:
- 描述:使用最近邻插值$(Nearest \space Neighbor)$算法,令变换后目标图像中某像素点的灰度值等于其原图像中距离其最近的像素点的灰度值。即,将原图像中的像素点映射到目标图像中的像素点,并为其设置相同的灰度值。
-
公式:$W$表示图像宽度,$H$表示图像高度,$X,Y$为横纵坐标
\[X_{src} = X_{dst} * \frac{W_{src}}{W_{dst}} \\ Y_{src} = Y_{dst} * \frac{H_{src}}{H_{dst}}\]
-
代码:
import cv2 as cv import numpy as np import math # 使用最近邻插值作为默认像素值变换算法 def my_imresize(src, dsize, dst=None): # 注意计算机图像里宽X对应的是列col,高Y对应的是行row,而shape=(row高,col宽,channels通道数) W_src, H_src = src.shape[1], src.shape[0] # 但是输入的是符合常识的 宽*高 模式即(width, height) W_dst, H_dst = dsize[0], dsize[1] # 计算X与Y轴上的图像变换比例 scale_X, scale_Y = W_src / W_dst, H_src / H_dst # 创建三通道矩阵存储目标图像,注意cv2是以BGR通道读取的图像,且像素值是无符号8位整型 dstImg = np.zeros(shape=(H_dst, W_dst, 3), dtype=np.uint8) # 使用math.floor对映射值进行下取整,防止出现边缘进位超出索引范围 for X_dst in range(0, W_dst): X_src = math.floor(X_dst * scale_X) for Y_dst in range(0, H_dst): Y_src = math.floor(Y_dst * scale_Y) # 对于其三个通道而言 for c in range(3): dstImg[Y_dst][X_dst][c] = src[Y_src][X_src][c] # 若指明目标图像,则存储在指定对象中,否则返回新目标图像 if dst is not None: dst = dstImg else: return dstImg -
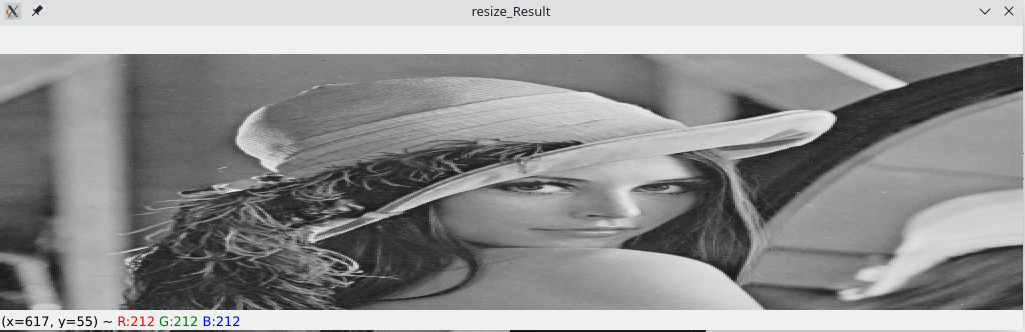
测试: 原图像是Lena的512x512分辨率的灰度图像,其实使用彩色图像也是一样的,
cv::imread函数如果不指明flags=cv2.IMREAD_GRAYSCALE,默认是以忽略透明度$\alpha$通道的彩色三通道图片方式读取,如果原图是灰度图像,会在BGR三个通道上复制相同的灰度值if __name__ == '__main__': srcImg = cv.imread("./resource/lena512.bmp") cv.imshow("Original_IMG", srcImg) dstImg = my_imresize(src=srcImg, dsize=(1024, 256)) cv.imshow("resize_Result", dstImg) cv.waitKey(0) cv.destroyAllWindows()
2.图像旋转
-
描述:在一幅大小为$M \times N$的灰度图像$I$中,现将其逆时针旋转$A$度,得到图像$J$
- 算法:
-
描述: 二维图像进行旋转是绕着某个点进行旋转,最朴素的方法便是绕着图像的原点进行旋转,如图2.1所示
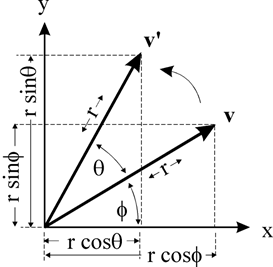
图中$\theta$即旋转角度,点$v$绕原点旋转$\theta$角得到点$v^{‘}$,其中$v$点坐标为$(x, y)$,则$v^{‘}$点的坐标$(x^{‘}, y^{‘})$由如下公式得到:
\[\begin{array}{c c} x = \vec{r}\cos{\phi} & x' = \vec{r}\cos{(\theta + \phi)} = \vec{r}\cos{\theta}\cos{\phi} - \vec{r}\sin{\theta}\sin{\phi} = x\cos{\theta} - y\sin{\theta} \\ y = \vec{r}\sin{\phi} & y' = \vec{r}\sin{(\theta + \phi)} = \vec{r}\sin{\theta}\cos{\phi} + \vec{r}\cos{\theta}\sin{\phi} = x\sin{\theta} + y\cos{\theta} \\ \end{array} \\ \Downarrow \\ \begin{bmatrix} x' \\ y' \end{bmatrix} = \begin{bmatrix} \cos{\theta} & -\sin{\theta} \\ \sin{\theta} & \cos{\theta} \end{bmatrix} * \begin{bmatrix} x \\ y \end{bmatrix}\]只需知道旋转角度$\theta$,计算其对应的旋转矩阵$M$,利用$M$左乘坐标向量即可得到新的坐标向量 但是该矩阵仅对应于旋转中心点为图片原点的情况,为了泛化旋转方式,使图像能够绕着给定的图像中任一点进行旋转,可以将这种情况转换为绕原点旋转的情况
- 移动图像,使旋转点与原点重合
- 执行旋转
- 移动新图像,复原旋转点位置
即处理绕任意点进行旋转的情况需要执行两次平移操作。假设平移变换的矩阵为$T(x,y)$,旋转变换的矩阵为$R(x,y,\theta)$,每执行一次变换都是将对应的变换矩阵左乘坐标向量,则有:
\[\vec{v'} = T(x, y)R(x, y, \theta)T(-x, -y)\vec{v}\]其中$T(-x,-y)$表示将图像平移至旋转点与原点重合的平移矩阵,$T(x,y)$即旋转变换完毕后将旋转点复位的平移矩阵
利用齐次坐标(Homogeneous Coordinates)将平移、旋转、缩放统一使用矩阵表示,将二维坐标扩充至3维,并使第三维$w=1$,原坐标$(x,y)$在齐次坐标中表示为列向量$ [x,y,1]^{\mathrm{T}} $,则平移变换$ x’=x+t_x,y’=y+t_y $可以转换为齐次坐标下的矩阵表示
\[\begin{bmatrix} x' \\ y' \\ 1 \end{bmatrix} = \begin{bmatrix} x+t_x \\ y+t_y \\ 1\end{bmatrix} = \begin{bmatrix} 1 & 0 & t_x \\ 0 & 1 & t_y \\ 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} x \\ y \\ 1 \end{bmatrix} \to T(t_x, t_y) = \begin{bmatrix} 1 & 0 & t_x \\ 0 & 1 & t_y \\ 0 & 0 & 1 \end{bmatrix}\]且将朴素方法中的旋转变换也扩充到齐次坐标形式:
\[\begin{bmatrix} x' \\ y' \\ 1 \end{bmatrix} = \begin{bmatrix} \cos{\theta} & -\sin{\theta} & 0 \\ \sin{\theta} & \cos{\theta} & 0 \\ 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} x \\ y \\ 1 \end{bmatrix} \to R(x,y,\theta) = \begin{bmatrix} \cos{\theta} & -\sin{\theta} & 0 \\ \sin{\theta} & \cos{\theta} & 0 \\ 0 & 0 & 1 \end{bmatrix}\]最终可得绕任一点进行旋转的旋转矩阵$M$:
\[\begin{aligned} M &= T(t_x,t_y)R(x,y,\theta)T(-t_x,-t_y) \\ &= \begin{bmatrix} 1 & 0 & t_x \\ 0 & 1 & t_y \\ 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} \cos{\theta} & -\sin{\theta} & 0 \\ \sin{\theta} & \cos{\theta} & 0 \\ 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} 1 & 0 & -t_x \\ 0 & 1 & -t_y \\ 0 & 0 & 1 \end{bmatrix} \\ &= \begin{bmatrix} \cos{\theta} & -\sin{\theta} & t_x(1-\cos{\theta}) + t_y\sin{\theta} \\ \sin{\theta} & \cos{\theta} & -t_x\sin{\theta} + t_y(1-\cos{\theta}) \\ 0 & 0 & 1 \end{bmatrix} \end{aligned}\]在数字图像处理中,给定旋转点$P(c_x,c_y)$时,其平移量$t_x=c_x$,$t_y=c_y(c_x,c_y > 0)$
而OpenCV的
\[M_{cv} =\begin{bmatrix} \alpha & \beta & c_x(1 - \alpha) - c_y\beta \\ -\beta & \alpha & c_x\beta + c_y(1 - \alpha) \end{bmatrix} \\ \alpha=scale*cos(angle) \\ \beta=scale*sin(angle)\]cv::getRotationMatrix2D函数根据输入的旋转中心点(cx,cy)、角度angle和缩放比例scale生成旋转矩阵$M_{cv}$比较$M$与$M_{cv}$可发现,OpenCV生成的旋转矩阵$M_{cv}$对应于上述推导得到的$M$的子矩阵$M[0:2]$,由于只做单纯的旋转,所以将
scale定为1,且有$angle=-\theta$(利用$\sin(-\theta)=\sin{\theta}$),即OpenCV的旋转矩阵生成函数中的参数angle是以逆时针为正角度的(以数字图像处理中常用的二维图像坐标系为例,原点在图像左上角,y轴指向下方,x轴指向右方,在这个坐标系下的逆时针为旋转角度angel的正向,将前述推导中的标准坐标轴沿X轴反转,其实是以顺时针作为旋转角度$\theta$的正向)显然利用该矩阵,可以轻松进行旋转的坐标变换。但是,还有一些细节需要处理,旋转过程如下图所示,还要对旋转后生成的图像执行一次平移,使新图像的原点与原图像原点重合
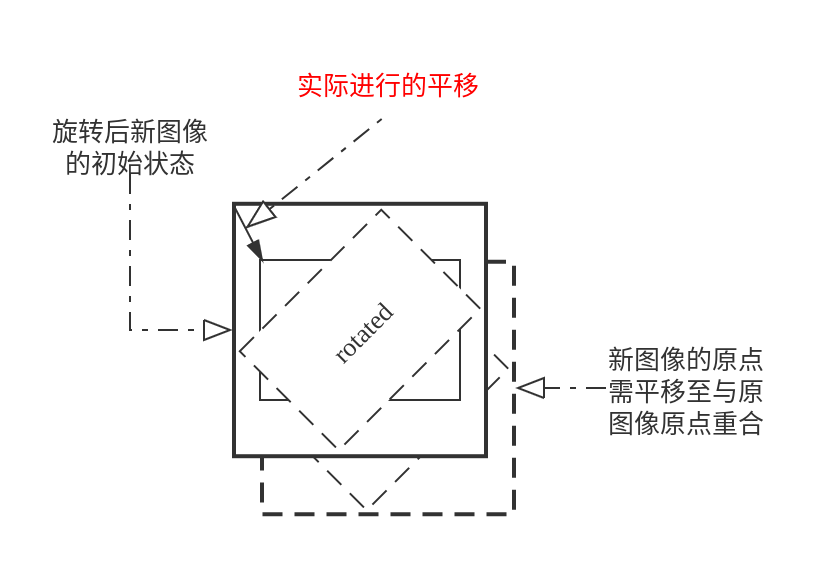
仿射变换的原理是一个非奇异的线性变换+平移,前述推导得到的变换矩阵$M$就满足:
\[\begin{bmatrix}x' \\ y' \\ 1 \end{bmatrix} = M \begin{bmatrix} x \\ y \\ 1 \end{bmatrix} \xrightarrow{\textrm{将M简写为分块矩阵形式}} \vec{x'} = M\vec{x} = \begin{bmatrix} \bold{A} & \bold{t} \\ \bold{0^\mathrm{T}} & 1 \end{bmatrix} \vec{x}\]上式中,$\bold{A}$是线性变换部分且非奇异,而$\bold{t}$是平移向量。如果再添加一个平移变换,只需给平移向量$\bold{t}$加上新的平移量,这部分平移量又可以表示为$t_x’=c_x’-c_x,t_y’=c_y’-c_y$,即新的平移向量$\bold{t’}=\bold{t} + [t_x’, t_y’]^\mathrm{T}$
-
-
代码:
# 旋转图片,注意不能裁剪图片,在适当位置补上0灰度值,使整个图片得到旋转而背景为黑色 def my_imrotate(src, theta, dst=None): # 获取原图像高和宽 (h, w) = src.shape[:2] # 获取图像旋转中心点坐标 (c_x, c_y) = (w // 2, h // 2) # 计算旋转后的矩阵 # OpenCV生成的旋转矩阵 # M_cv = cv.getRotationMatrix2D((c_x, c_y), -theta, 1.0) # 自己计算旋转矩阵,dtype默认为np.float64 M = np.zeros((2, 3)) # 参数中给定的theta是角度值,要转换为弧度才可用于三角函数计算 theta = math.radians(theta) cos_theta = math.cos(theta) sin_theta = math.sin(theta) M[0,0] = M[1,1] = cos_theta M[1,0], M[0,1] = sin_theta, -sin_theta M[0,2] = c_x*(1 - cos_theta) + c_y*sin_theta M[1,2] = c_x*(-sin_theta) + c_y*(1 - cos_theta) # 比较两个矩阵 # print("M_cv: {}".format(M_cv)) # print("M: {}".format(M)) # 计算旋转后新图像的大小,注意要将负的正余弦值转换为绝对值 sin_theta = abs(sin_theta) cos_theta = abs(cos_theta) nW = int((h * sin_theta) + (w * cos_theta)) nH = int((h * cos_theta) + (w * sin_theta)) # 调整变换矩阵中平移向量的值 # 由于实际图像与原图像的原点要重合,还要加上原图像旋转点到新图像旋转点的平移量,这里旋转点固定为中心点 M[0,2] += (nW // 2) - c_x M[1,2] += (nH // 2) - c_y # 利用仿射变换 if dst is not None: dst = cv.warpAffine(src, M, (nW, nH)) else: return cv.warpAffine(src, M, (nW, nH)) -
测试 旋转矩阵计算的旋转角以顺时针为正向,灰度图像顺时针旋转60度,彩色图像逆时针旋转120度
if __name__ == '__main__': # 灰度图像,设置cv::IMREAD_GRAYSCALE指明以灰度单通道方式读入 srcImg = cv.imread("./resource/lenna.png", flags=cv.IMREAD_GRAYSCALE) dstImg = my_imrotate(src=srcImg, theta=60) # 彩色图像,OpenCV默认以BGR通道读入 srcImg_bgr = cv.imread("./resource/lenna.png") dstImg_bgr = my_imrotate(src=srcImg_bgr, theta=-120) # BGR通道的彩色图像要使用matplotlib::imshow显示,需要转换为RGB通道 dstImg_rgb = cv.cvtColor(dstImg_bgr, code=cv.COLOR_BGR2RGB) plt.subplot(211), plt.imshow(dstImg, cmap=plt.cm.gray) plt.title('Grayscale Img'), plt.xticks([]), plt.yticks([]) plt.subplot(212), plt.imshow(dstImg_rgb) plt.title('RGB Img'), plt.xticks([]), plt.yticks([]) plt.show()
图像灰度变换
4.直方图规定化
-
描述 设一副大小为$M \times N$的灰度图像$I$中,灰度为$g$的像素数为$h(g), 0 \leq g \leq 255$。 另给定一个直方图$t(g), 0 \leq g \leq 255$。请写出对图像$I$进行变换的方法,使得变换后的新图像直方图与$t$近似相同。注意,只测试灰度图像。
- 算法
-
描述: 在直方图均衡化中,对于连续灰度值(连续型随机变量)的基本描绘子是其概率密度函数(PDF),均衡化是寻找一个映射函数,使其映射后新图像的PDF呈现完全均匀的状态。设变量$r,s$分别为原图像和新图像的灰度,$p_r(r)与p_s(s)$分别表示各自的PDF,$s=T(r)$是需要寻找的目标映射函数,那么有公式$p_s(s)=p_r(r)|\frac{dr}{ds}|$将二者PDF联系起来,这个变换函数通常使用变量$r$的累积分布函数(CDF):
\[s=T(r)=(L-1)\int_{0}^{r}p_r(w)dw \\[5px] T(r)\textrm{在区间}r\in[0,L-1]\textrm{上单调递增} \\[5px] \frac{ds}{dr}=\frac{dT(r)}{dr}=(L-1)\frac{d}{dr}[\int_{0}^{r}p_r(w)dw]=(L-1)p_r(r) \\[5px] \textrm{利用PDF间的变换公式就可得到一个具有均匀PDF的新图像} \\[5px] p_s(s)=p_r(r)|\frac{dr}{ds}|=p_r(r)|\frac{1}{(L-1)p_r(r)}|=\frac{1}{L-1},s \in [0,L-1] \\[5px] \textrm{对于通常情况下的离散灰度图像,可以以离散值求和来替代积分} \\[5px] p_r(r_k)=\frac{n_k}{MN}, k=0,1,2,\cdots,L-1 \\ s_k=T(r_k)=(L-1)\sum_{j=0}^{k}p_r(r_j)=\frac{L-1}{MN}\sum_{j=0}^{k}n_j, k=0,1,2,\cdots,L-1 \tag{4.1}\]对于直方图规定化而言,假设仍在连续灰度下进行考量,另一幅给定灰度图像的PDF为$p_z(z)$,即找到一个映射函数,使原图像的PDF:$p_r(r)$经过映射后具有指定的PDF:$p_z(z)$,根据$z$的CDF函数同样有$s=G(z)=(L-1)\int_{0}^{z}p_z(t)dt$,可得$G(z)=T(r) \to z=G^{-1}(s)=G^{-1}[T(r)]$,据此可得到从输入灰度$r$到输出灰度$z$的一步变换。
同样,在离散情况下,给定一个规定的$s_k$值,$k,q$分别是输出图像和原图像的某一灰度级,则有:
\[G(z_q)=(L-1)\sum_{i=0}^{q}p_z(z_i)=s_k \tag{4.2}\] \[p_z(z_i)\textrm{为规定的直方图的第}i\textrm{个值},\textrm{利用反变换找到期望的值}z_q \\[5px] z_q=G^{-1}(s_k)\]根据前述推导可知,离散形式下直方图规定化过程如下:
- 计算给定图像的直方图$p_r(r)$,并寻找式$(4.1)$的直方图均衡变换,且$round(s_k)\in Z \cap [0,L-1]$。
- 用式$(4.2)$对$q=0,1,2,\cdots,L-1$计算变换函数$G(z_q)$的所有输出值,计算并存储$round[G(z_q)] \in Z \cap [0, L-1]$。
- 对每一个$s_k,k=0,1,2,\cdots,L-1$,寻找一个最接近的$G(z_q)$值,并存储从$s \to z$的映射。当满足给定$s_k$的$z_q$值多于一个时,按惯例选择最小的值。
- 使用步骤3中得到的映射将每个原图像均衡化后的像素值$s_k$映射到规定化目标图像的$z_q$,和步骤1得到的$r \to s$的映射合并后即有$r \to z$的映射。
在实际操作中,对于$s_k,z_q$,一般是找使$ s_k - G(z_q) $最小的映射$s_k \to z_q$
-
-
代码:
# 给定图像,计算其直方图,对于k比特图像,L=2^k def my_histogram(img, L) -> List[int]: hist = np.array([0 for i in range(L)]) (h, w) = img.shape[:2] for i in range(h): for j in range(w): hist[img[i][j]] += 1 return hist # 给定直方图,计算其累积分布函数CDF # hist为给定的直方图,size为图像的像素点个数, L=2^k def my_cdf(hist, size, L) -> List[float]: # 自己计算,不使用[np.cumsum(hist, dtype=float) / cumsum.max()] cdf = [] cdf.append(hist[0] / size) for i in range(0, L-1): cdf.append(cdf[i] + hist[i+1] / size) return cdf def my_histogram_match(original, specified, dst=None): (h, w) = original.shape[:2] # 首先计算原图像的直方图,一般是8bit图像,即256个灰度级 hist_1 = my_histogram(img=original, L=256) # 计算原图像的累积分布函数CDF cdf_1 = my_cdf(hist=hist_1, size=original.size, L=256) # 计算s_k=T(r)=(L-1)CDF(r),注意要将List转换为ndarray,否则不能将CDF中各值同时乘一个数放大 s = np.around(255*np.array(cdf_1)) # 计算目标图像的直方图 hist_2 = my_histogram(img=specified, L=256) # 计算目标图像的CDF cdf_2 = my_cdf(hist=hist_2, size=specified.size, L=256) # 计算G(z_q)=(L-1)CDF(z) G_z = np.around(255*np.array(cdf_2)) # 寻找使r->s_k, s_k->z_q的最接近映射,其满足|s_k - G(z_q)|最小 # 计算s与G(z)的差值 diff = [[0 for k in range(256)] for q in range(256)] for k in range(256): for q in range(256): diff[k][q] = abs(s[k] - G_z[q]) # 进行映射(Mapping) mapping = [0 for i in range(256)] # 寻找s_k到z_q的最佳映射,k,q∈[0, L-1] for k in range(256): cor_q = np.argmin(diff[k]) mapping[k] = cor_q dstImg = original.copy() # 进行灰度映射 for i in range(h): for j in range(w): dstImg[i, j] = mapping[original[i, j]] if dst is not None: dst = dstImg else: return dstImg -
测试 仍然是
Lena512.bmp,目标图像任意使用# 注意,仅处理灰度图像,对于彩色图像使用灰度方式读取 srcImg = cv.imread("./resource/lena512.bmp", flags=cv.IMREAD_GRAYSCALE) mask = cv.imread("./resource/gray-gradient.jpg", flags=cv.IMREAD_GRAYSCALE) result = my_histogram_match(srcImg, mask) xticks = range(0, 256, 32) plt.subplot(321), plt.imshow(srcImg, cmap=plt.cm.gray) plt.title('Source Image'), plt.xticks([]), plt.yticks([]) plt.subplot(322), plt.hist(srcImg.ravel(), 256) plt.title('Source Histogram'), plt.xticks(xticks) plt.subplot(323), plt.imshow(mask, cmap=plt.cm.gray) plt.title('Destination Image'), plt.xticks([]), plt.yticks([]) plt.subplot(324), plt.hist(mask.ravel(), 256) plt.title('Destination Histogram'), plt.xticks(xticks) plt.subplot(325), plt.imshow(result, cmap=plt.cm.gray) plt.title('Result Image'), plt.xticks([]), plt.yticks([]) plt.subplot(326), plt.hist(result.ravel(), 256) plt.title('Result Histogram'), plt.xticks(xticks) plt.show()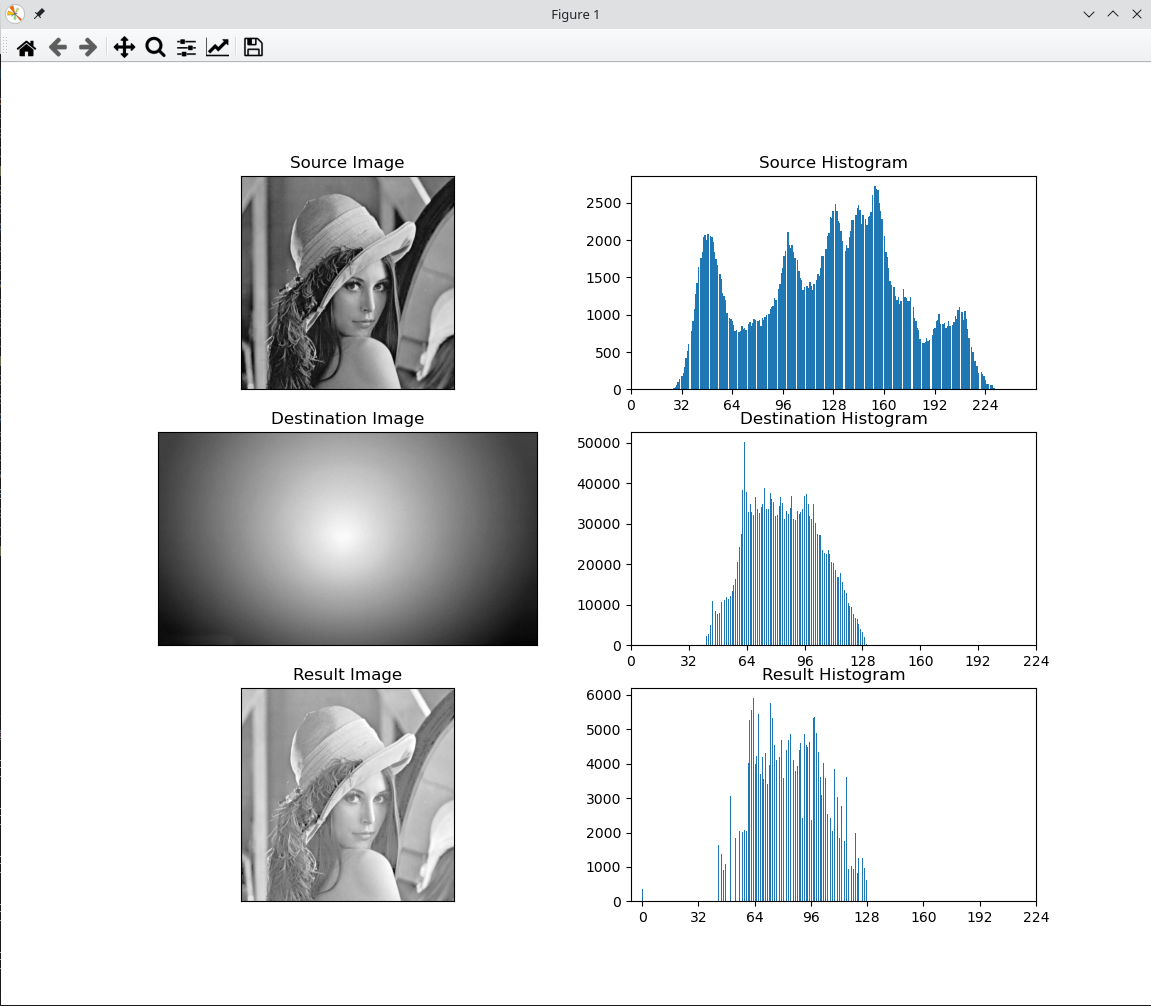
频域滤波
17.基于频域滤波的基本步骤
-
描述:写出基于频域的低通滤波的步骤。编写程序(允许调用
FFT,IFFT等库函数),实现基于频域的滤波 - 算法:
-
描述: 给定大小为$M \times N$的输入图像$f(x,y)$,其$DFT$为$F(u,v)$,设频域中的滤波函数为$H(u,v)$,在频域进行滤波其实就是将$F$与$H$相乘并对结果进行$IDFT$还原到空域即可,但是涉及一些细节需要处理,步骤如下:
-
根据卷积定理:$F(u,v)H(u,v) \Leftrightarrow f(x,y) \star h(x,y)$,为了防止频域滤波器在空间域与原图像进行卷积时产生缠绕错误(周期函数相互卷积会被来自邻近周期的数据干扰卷积结果),首先对原图像进行零填充,一般选择2倍长宽扩展,即$P=2M,Q=2N$,扩展出的像素点全部填充0以形成大小为$P \times Q$的图像$f_p(x,y)$。
-
考虑DFT的周期性和滤波目标,如果变换区域中能够获得$F(u,v)$的一个数据连续的完整周期,将更有利于滤波计算。根据傅里叶变换的平移性$f(x,y)e^{j2\pi(u_{0}x/M+v_{0}y/N)} \Leftrightarrow F(u-u_{0},v-v_{0})$,为了使$F(0,0)$移动到频率域矩形中心$(u_{0},v_{0})=(M/2,N/2)$,则有$f(x,y)(-1)^{x+y} \Leftrightarrow F(u-M/2,v-N/2)$。即,用$(-1)^{x+y}$乘以$f_p(x,y)$将扩充后图像的DFT移到频率域矩形中心$(P/2, Q/2)$处。
-
计算上一步得到的图像的DFT,得到频域里的$F(u,v)$。
-
生成一个关于频域矩形区域中心点实对称的滤波函数$H(u,v)$,其大小也为$P \times Q$,中心也在$(P/2, Q/2)$处。这里使用低通滤波器,以理想低通滤波器(ILPF)为滤波函数:
\[H(u,v) = \left\{ \begin{array}{c c c} 1, & & D(u,v) \leq D_0 \\ 0, & & D(u,v) > D_0 \end{array} \right.\]其中$D_0$是一个正常数,$D(u,v)$表示频率域中点$(u,v)$与频率矩形中心$(P/2,Q/2)$的距离:
\[D(u,v) = \left[ (u-P/2)^2 + (v-Q/2)^2 \right]^{\frac{1}{2}}\] -
使用元素乘(Element-wise Product)计算乘积$G(u,v)=H(u,v)F(u,v)$
-
利用$IDFT$将滤波结果还原到空间域,同时再乘以第二步中的平移量,使滤波结果的中心点移回左上角原点,形成图像
\[g_p(x,y)=\left\{\Re \left[\mathscr{F}^{-1}[G(u,v)] \right] \right\}(-1)^{x+y}\]注意其中取的是反变换后函数的实部,这是为了忽略由于计算不准确导致的寄生复分量。
-
从$g_p(x,y)$的左上象限提取$M \times N$区域,得到最终的处理结果$g(x,y)$
-
-
公式: 对于大小为$M \times N$的数字图像$f(x,y)$,其二维离散傅里叶变换对如下所示
\[\textrm{二维离散傅里叶变换}(DFT) \\[5px] F(u, v) = \sum_{x=0}^{M-1}\sum_{y=0}^{N-1}f(x,y)e^{-j2\pi(ux/M+vy/N)} \\[5px] \textrm{二维离散傅里叶反变换}(IDFT) \\[5px] f(x, y) = \frac{1}{MN}\sum_{u=0}^{M-1}\sum_{v=0}^{N-1}F(u,v)e^{j2\pi(ux/M+vy/N)} \\[5px] (x,y)\textrm{为空间域变量}\left\{\begin{array}{c} x=0,1,2,\cdots,M-1 \\ y=0,1,2,\cdots,N-1 \end{array} \right. \\[5px] (u,v)\textrm{为频率域变量}\left\{\begin{array}{c} u=0,1,2,\cdots,M-1 \\ v=0,1,2,\cdots,N-1 \end{array} \right.\]
-
-
代码:
# 获取理想低通滤波器ILPF(Ideal Low-Pass Filter) def create_ILPF(shape, radius: int): rows, cols = shape[:2] kernel = np.zeros(shape, dtype=np.uint8) center = (cols // 2, rows // 2) # 计算各像素点在高和宽方向上距中心点x,y方向上的距离 dis_h, dis_w = np.mgrid[0:rows:1, 0:cols:1] dis_h -= center[1] dis_w -= center[0] D = np.power(dis_h, 2.0) + np.power(dis_w, 2.0) D_0 = pow(radius, 2) # 低频通过,高频截断,滤波器中心以radius为半径的圆内H(u,v)=1 kernel[D <= D_0] = 1 return kernel # 频率域低通滤波 def low_pass_filter_in_fourier(src, radius): """ @return spectrum: 图像的频谱(傅里叶谱) @return kernel: 使用的滤波器核 @return g: 滤波结果 """ # 长宽扩充2倍且进行零填充 rows, cols = src.shape[:2] f = np.zeros((rows * 2, cols * 2), dtype=np.uint8) f[:rows, :cols] = src F = np.fft.fft2(f) # 利用快速傅里叶变换得到DFT F_shift = np.fft.fftshift(F) # 将F(0,0)移至频率域矩形中心,即,将直流分量移至傅里叶谱的中心 ''' 观察频谱,由于直流分量|F(0,0)|是傅里叶谱的最大分量,有可能比其他项大几个数量级 故取对数,归一化后将幅度映射到0~255,abs取绝对值就是计算频谱中该项(复数)的幅度 ''' spectrum = np.log(np.abs(F_shift)) spectrum = cv.normalize(spectrum, 0, 1, norm_type=cv.NORM_MINMAX, dtype=cv.CV_32F) spectrum *= 255 kernel = create_ILPF(shape=f.shape, radius=radius) # 获取ILPF G = F_shift * kernel # 计算滤波结果G(u,v)=H(u,v)F(u,v) G_shift = np.fft.ifftshift(G) # 将直流分量移回原点 g = np.fft.ifft2(G_shift) # 执行IDFT g = np.real(g) # 忽略寄生复分量,仅保留实部 g = g[:rows, :cols] # 从左上象限提取MxN区域,获得最终处理结果 return spectrum, kernel, g -
测试: 依然使用Lena图,原图为
512x512大小,ILPF选择radius=128if __name__ == '__main__': # 频率域滤波:理想低通滤波 srcImg = cv.imread("./resource/lenna.png", flags=cv.IMREAD_GRAYSCALE) radius = 128 spectrum, kernel, g = low_pass_filter_in_fourier(src=srcImg, radius=radius) plt.subplot(221), plt.imshow(srcImg, cmap='gray') plt.title('Source Image'), plt.xticks([]), plt.yticks([]) plt.subplot(222), plt.imshow(spectrum, cmap='gray') plt.title('Normalized Spectrum'), plt.xticks([]), plt.yticks([]) plt.subplot(223), plt.imshow(kernel, cmap='gray') plt.title('ILPF Kernel (radius={})'.format(radius)) axis = plt.gca() axis.xaxis.set_ticks_position('top') # x轴移至子图上方 axis.yaxis_inverted() # 反转y轴 plt.subplot(224), plt.imshow(g, cmap='gray') plt.title('Result Image'), plt.xticks([]), plt.yticks([]) plt.show()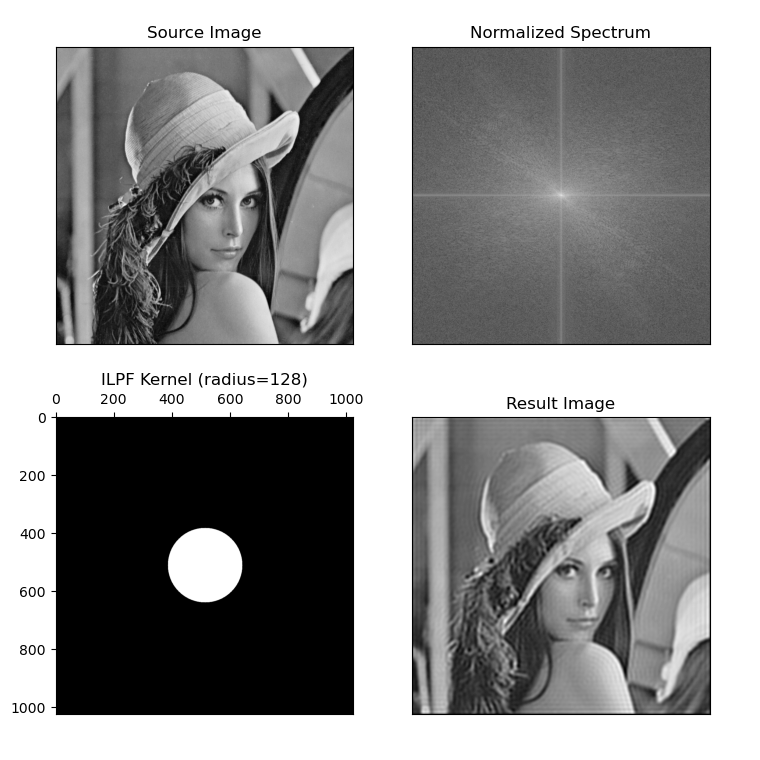
边缘检测
20.请写出Canny算子检测边缘的详细步骤
- 算法步骤:
-
对给定图像$f(x,y)$进行高斯滤波去除噪声,这一步的目的是防止噪声这一灰度变化较大的区域被识别为伪边缘
-
使用梯度算子,计算图像梯度,得到灰度变化最明显的区域,作为待定边缘集合。采用Sobel算子滑过整个图像,相当与做二维离散卷积,相关计算式如下
\[\begin{aligned} \textrm{水平算子}: Sobel_x &= \begin{bmatrix} 1 \\ 0 \\ -1 \end{bmatrix} \times \begin{bmatrix} 1 & 2 & 1 \end{bmatrix} = \begin{bmatrix} 1 & 2 & 1 \\ 0 & 0 & 0 \\ -1 & -2 & -1 \end{bmatrix} \\[5px] \textrm{垂直算子}: Sobel_y &= \begin{bmatrix} 1 \\ 2 \\ 1 \end{bmatrix} \times \begin{bmatrix} 1 & 0 & -1 \end{bmatrix} = \begin{bmatrix} 1 & 0 & -1 \\ 2 & 0 & -2 \\ 1 & 0 & -1 \end{bmatrix} \\[5px] G_x(x,y) &= f(x,y) \star Sobel_x(x,y) \\ G_y(x,y) &= f(x,y) \star Sobel_y(x,y) \\ \textrm{图像梯度}: G(x,y) &= \sqrt{G_x^{2} + G_y^{2}} \\ \textrm{简化计算}: G(x,y) &\approx M(x,y) = |G_x|+|G_y| \\ \textrm{梯度方向}: \theta(x,y) &= arctan(\frac{G_x}{G_y}) \end{aligned}\] -
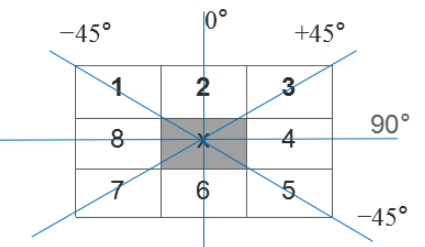
进行非极大值抑制。将某像素点局部区域的梯度方向上灰度变化最大的点保留下来,据此可以剔除大部分点,将“粗边缘”变成“瘦边缘”。具体操作为,在每个像素点位置,3x3区域内中心梯度$x$与沿着其对应梯度方向(一共4个方向,水平、垂直、双对角线)的两个像素点的梯度比较,若$x$已为最大值,则保留,否则$x$置0。计算$\theta(x,y)$后在每个点上将其弧度$\theta$转换为真实的角度值,根据角度值判断梯度方向,如下图所示:
-
双阈值筛选。设置两个阈值$T_h$和$T_l$分别表示高阈值和低阈值,灰度梯度大于$T_h$的设为强边缘像素点,低于$T_l$的认为不是边缘并剔除,处于$T_h$与$T_l$之间的设为弱边缘像素点,接着判断其8邻域内有无强边缘像素,若有则保留,否则剔除。这一步是为了补充强边缘轮廓有可能不闭合的缺点,使边缘尽可能闭合,一般$T_h:T_l=3:1$或$2:1$
-
-
代码:
# 获取Sobel算子 def getSobelKernel(): """ @return sobel_x: 水平算子 @return sobel_y: 垂直算子 """ op1 = np.array([[1, 0, -1]]) # 创建行向量op1 op2 = np.array([[1, 2, 1]]) # 创建行向量op2 sobel_x = op1.T @ op2 sobel_y = op2.T @ op1 return sobel_x, sobel_y # Canny边缘检测 def my_canny_edge_detect(src, TL=20, TH=60, dst=None): """ @param src: input image @param TL: Threshold Low,default=20.For double-threshold algorithm. @param TH: Threshold High,default=60.Like above. @return res_edge: Edge detection result """ # Step1:利用cv::GaussianBlur进行图像降噪 src = cv.GaussianBlur(src, (5, 5), 0) # Step2:利用Sobel梯度算子计算图像梯度 sobel_x, sobel_y = getSobelKernel() # 利用cv::filter2D实现滤波核在二维图像上的滑动计算,注意这里要求使用的kernel的数据类型为浮点矩阵 # 注意ddepth为目标深度,由于原图像一般为uint8的8比特灰度图像,算子滑过时也有可能产生负值,如果使用默认ddepth=-1则会丢失负值 G_x = cv.filter2D(src, ddepth=cv.CV_64F, kernel=sobel_x.astype(np.float64)) G_y = cv.filter2D(src, ddepth=cv.CV_64F, kernel=sobel_y.astype(np.float64)) # 计算简化的梯度幅值M(x,y)=|G_x|+|G_y| M = np.abs(G_x) + np.abs(G_y) # 计算各像素点对应的梯度方向,注意要根据具体值选择象限,不能使用值域为[-pi/2,pi/2]的np.arctan函数 theta = np.arctan2(G_x, G_y) # 弧度转换为角度值 theta = np.degrees(theta) # Step3:开始非极大值抑制(non-maximum suppression) h, w = M.shape[:2] M_noMax_sup = np.zeros((h+2, w+2)) # 创建一个扩充了一层边界的零矩阵,用于非极大值抑制 M_noMax_sup[1:h+1, 1:w+1] = M # 边界都为0,中心还是M # 为了保持利用梯度方向theta判断时索引的一致性,这里i,j范围为原图像高宽 for i in range(0, h): for j in range(0, w): mag = M_noMax_sup[i+1][j+1] # 拿到对应索引处的幅度值 angle = theta[i][j] # 角度判断用 angle_abs = abs(angle) # op1和op2表示当前像素点幅度将要比较的其他幅度 # 垂直梯度->水平边缘,比较上下梯度 if angle_abs <= 22.5 or angle_abs >=157.5: op1 = top = M_noMax_sup[i][j+1] op2 = down = M_noMax_sup[i+2][j+1] # 水平梯度->垂直边缘,比较左右梯度 elif 67.5 <= angle_abs or angle_abs <= 112.5: op1 = left = M_noMax_sup[i+1][j] op2 = right = M_noMax_sup[i+1][j+2] # +45度边缘,比较左下和右上 elif (112.5 < angle < 157.5) or (-67.5 < angle < -22.5): op1 = left_down = M_noMax_sup[i+2][j] op2 = right_top = M_noMax_sup[i][j+2] # -45度边缘,比较右下和左上 else: op1 = right_down = M_noMax_sup[i+2][j+2] op2 = left_top = M_noMax_sup[i][j] if mag < op1 or mag < op2: M_noMax_sup[i+1][j+1] = 0 # 非极大值,抑制为0 M = M_noMax_sup[1:h+1, 1:w+1] # 抑制完毕后更新M # Step4:双阈值处理 edge = np.zeros(M.shape[:2]) for i in range(0, h): for j in range(0, w): mag = M[i][j] if mag >= TH: edge[i][j] = 255 # 标记为强边缘 if TL < mag < TH: edge[i][j] = 100 # 标记为弱边缘 # if mag <= TL: edge[i][j]=0 省略,本来就是0 # 处理上一步中得到的弱边缘,用8邻域内是否含有强边缘点判断,没有则赋0 res_edge = edge.copy() # 先复制一份,因为操作过程中不能直接在原待定边缘矩阵上更改标记值 for i in range(1, h-1): for j in range(1, w-1): if edge[i][j] == 100: adjacent = edge[i-1:i+2, j-1:j+2] # 3x3矩阵展平为一维列向量后用np.max查找最大值,小于255说明邻域内没有强边缘点 if np.max(np.reshape(adjacent, -1)) != 255: res_edge[i][j] = 0 else: res_edge[i][j] = 255 return res_edge -
测试: 还是lena图
if __name__ == '__main__': # Canny边缘检测 srcImg = cv.imread("./resource/lenna.png", flags=cv.IMREAD_GRAYSCALE) res_edge = my_canny_edge_detect(srcImg) plt.subplot(121), plt.imshow(srcImg, cmap='gray') plt.title('Source Image'), plt.xticks([]), plt.yticks([]) plt.subplot(122), plt.imshow(res_edge, cmap='gray') plt.title('My Canny Edge Detection'), plt.xticks([]), plt.yticks([]) plt.show()
形态运算
21.区域标记
-
描述:设有一幅二值图像,请给出生成该图像对应的标记图像的方法。即按顺序排列图像的连通区域,将第$k$个连通区域的每一个白色像素的值置为$k$,$k=1,2,\cdots$,可不考虑区域编号的顺序
-
算法:
-
描述: 一个连通区域是由具有相同像素值的相邻像素点组成的点集合。对于一幅二值图像,采用两遍扫描法(Two Pass)找到所有不同的连通区域,两趟扫描过程都遵循自左向右、自上而下的按行扫描方式:
- 第一趟扫描:
访问当前像素点$P_i$,当扫描到白色像素点($P_i=1$)时
- 如果$P_i$的4邻域中各邻居的label都为0,则标记$P_i$(给予新的连通区域标记label):$label += 1$,$Label(P_i)=label$
-
如果$P_i$的邻域含有label不为0的邻居(同时它们也是白色像素点):
-
选择拥有最小label的邻居,并标记当前$P_i$与该邻居在同一连通区域内,$Label(P_i)=min{Label(P_{neighbors}) \mid P_{neighbors} = 1}$
-
记录当前4邻域内各个label之间的相等关系,即某些不同的label其实属于同一连通区域
-
注意,由于扫描顺序其实是按行扫描的,其实只要比较左边像素点和上方像素点即可
- 第二趟扫描: 将第一趟中得到的属于同一连通区域的label组所标记的像素归为一个连通区域,并赋予label组中的最小label值 访问当前像素点$P_i$,当扫描到白色像素点($P_i=1$)时,找到与$Label(P_i)$归属于同一连通区域的label组的label最小值,并更新赋值,即$Label(P_i)=min{ Label_{equivalent_area} }$
两趟扫描完毕后,就得到了所有的连通区域
- 第一趟扫描:
访问当前像素点$P_i$,当扫描到白色像素点($P_i=1$)时
-
代码:
# 连通区域标记 def connected_regions_label(src, dst=None): # 如果不是灰度图像则转换为灰度图像,RGB图像的shape为[rows, cols, channels=3] if src.shape[2] != 1: src = cv.cvtColor(src, cv.COLOR_BGR2GRAY) # 利用Otsu或者Triangle方法进行二值化,注意当采用这两种算法时,给定的固定阈值将失效 # 第一个返回值为Otsu/Triangle自行生成的特定阈值,第二个返回值为二值化结果图像 _, bw = cv.threshold(src, thresh=40, maxval=1, type=cv.THRESH_OTSU) h, w = bw.shape[:2] # 创建与原图像大小相等的存储标记值矩阵 # 只需比较左和上的像素点即可,因此扩充一行与一列边界 label_matrix = np.zeros((h+1, w+1), dtype=np.uint8) # label(P_i)=0表示该像素点不是白色像素点 cur_label = 0 # 待标记的label值 exclude_0 = np.array([0], dtype=np.uint8) # 用于在候选邻居label值中删去不为0的label值 equivs = [0] # 用index->value的形式记录等价对信息,注意是值才是前驱 # 注意label_matix的右下角h*w区域才是src_matrix # 即bw[i][j] <--> label_matrix[i+1][j+1],注意下标映射 # Step 1:第一趟扫描 for i in range(0, h): for j in range(0, w): if bw[i][j] == 1: left = label_matrix[i+1][j] top = label_matrix[i][j+1] if left == top == 0: # 邻居label都为0 cur_label += 1 # 产生新标记 equivs.append(cur_label) # 此时cur_label->cur_label label_matrix[i+1][j+1] = cur_label # 标记当前像素点 else: # 至少存在一个邻居的label不为0 labels = np.array([left, top], dtype=np.uint8) labels = np.setdiff1d(labels, exclude_0) min_label = np.min(labels) # 获得邻居的最小label值 label_matrix[i+1][j+1] = min_label # 以邻域最小label值标记 # 记录邻域label间的等价关系 for label in labels: if min_label != label: # 排除本身 if min_label < equivs[label]: # 如果label前驱的标号大于局部最小label equivs[label] = min_label # 前驱改为局部最小label equivs[equivs[label]] = min_label # 前驱的前驱也改为局部最小label elif min_label > equivs[label]: # 如果局部最小label大于当前label前驱 equivs[min_label] = equivs[label] # 局部最小label的前驱改为当前label前驱 # 更新所有等价对,消除传递等价 for idx, equiv in enumerate(equivs): curLabel = equiv preLabel = equivs[curLabel] while preLabel != curLabel: curLabel = preLabel preLabel = equivs[curLabel] equivs[idx] = curLabel label_matrix = label_matrix[1:h+1, 1:w+1] # 去除填充的边界 # Step 2:第二趟扫描 for i in range(0, h): for j in range(0, w): label_matrix[i][j] = equivs[label_matrix[i][j]] return label_matrix, equivs # 将已标记连通区域的label matrix添加随机颜色以区分 def colored_labels(labeled_img, equivs): h, w = labeled_img.shape[:2] res = np.zeros((h, w, 3), dtype=np.uint8) random_rgb = np.zeros((len(equivs), 3)) # 注意黑底区域(label=0)不赋予随机rgb值,故index从label=1开始 for i in range(1, len(random_rgb)): rgb = np.random.randint(0, 255, 3, dtype=np.uint8) random_rgb[i] = rgb for i in range(0, h): for j in range(0, w): res[i][j] = random_rgb[labeled_img[i][j]] return res -
测试: 用猫爪试一试,猫的脚垫刚好有5个连通区域
if __name__ == '__main__': # 区域标记 srcImg = cv.imread("./resource/cat_paw.jpg") regions, equivs = connected_regions_label(srcImg) res = colored_labels(regions, equivs) plt.subplot(121), plt.imshow(srcImg, cmap='gray') plt.title("Original Image"), plt.xticks([]), plt.yticks([]) plt.subplot(122), plt.imshow(res) plt.title("Colored Labeled Connected Regions"), plt.xticks([]), plt.yticks([]) plt.show()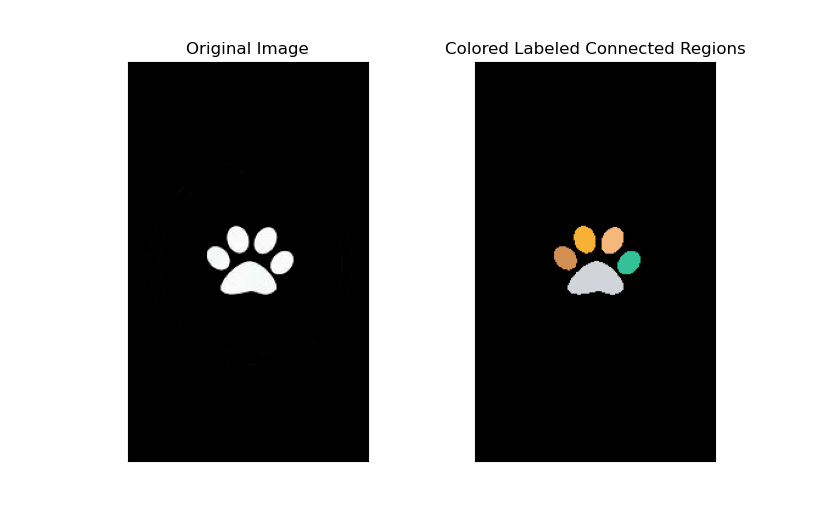
-
22.边界跟踪
-
描述:设一幅二值图像中只有一个白色区域,试给出求该区域外围轮廓线的方法,要求按顺时针的顺序给出各点坐标
-
算法:
- 描述:
该图像中只有一个白色区域,提取该区域的外围轮廓就可以采用边界跟踪算法,按照许老师的讲解,以逆时针方向进行边界跟踪算法依次找到边界点,最后倒序输出就达到了以顺时针顺序输出坐标的目的
-
对输入图像进行二值化处理,转为二值图像
-
对图像进行逐行查找(自上而下,自左而右),找到第一个值为1的点,即算法寻找的边界起始点,用$P_0$表示
-
定义方向变量$dir$(Direction),代表搜索方向,$dir=0,1,\cdots,7$。初始点$P_0$的初始搜索方向$dir=7$
\[\begin{array}{|c|c|c|} \hline 3 & 2 & 1 \\ \hline 4 & P_i & 0 \\ \hline 5 & 6 & 7 \\ \hline \end{array}\]以上为8邻域示意图,按照逆时针方向依次判断当前点$P_i$的8个相邻像素点是否为1,其中搜索的第一个邻居编号遵循以下规则:
- 如果当前$dir$为偶数,$dir_{start}=(dir + 7)mod8$
- 如果当前$dir$为奇数,$dir_{start}=(dir + 6)mod8$
从起始搜索方向$dir_{start}$开始,在8邻域中沿着逆时针方向找到第一个不为0的像素点作为新的边界点$P_n$,并且更新$dir=dir_{last}$,即找到该点时使用的方向
-
如果当前边界点$P_n$的坐标与$P_1$重合,且前一个边界点$P_{n-1}$的坐标与初始点$P_0$重合,则算法终止,否则重复第3步
-
-
代码:
# 边界跟踪 def boundary_tracking(src, dst=None): # 如果不是灰度图像则转换为灰度图像,RGB图像的shape为[rows, cols, channels=3] if src.shape[2] != 1: src = cv.cvtColor(src, cv.COLOR_BGR2GRAY) # 利用Otsu或者Triangle方法进行二值化,注意当采用这两种算法时,给定的固定阈值将失效 # 第一个返回值为Otsu/Triangle自行生成的特定阈值,第二个返回值为二值化结果图像 thresh, bw = cv.threshold(src, thresh=40, maxval=1, type=cv.THRESH_OTSU) rows, cols = src.shape[:2] res_img = np.zeros((rows, cols), dtype=np.uint8) # 利用numpy.where()函数找到所有值为1的点,当然此时只需要第一个点的坐标作为初始点P0 (x, y) = np.where(bw == 1) p0 = (x[0], y[0]) pi = p0 # 初始化当前边界点pi dir = 7 # 初始化搜索方向 boundary = [p0] # 初始化存储边界点的list initFlag = True # 标记边界追踪初始化情况,即边界点list只包含初始点的情况 # 8邻居对应当前点pi的两个方向上的偏移量(offset_x, offset_y),注意按照图中方向直接将dir作为索引 offsets = [(1,0),(1,-1),(0,-1),(-1,-1),(-1,0),(-1,1),(0,1),(1,1)] while initFlag or not(boundary[-1] == boundary[1] and boundary[-2] == boundary[0]): if dir % 2 == 0: cur_dir = (dir+7) % 8 else: cur_dir = (dir+6) % 8 # 一次性计算当前点对应的8个邻居像素点的坐标 temp = [(pi[0] + offset[0], pi[1] + offset[1]) for offset in offsets] while(bw[temp[cur_dir]] != 1): cur_dir = (cur_dir + 1) % 8 pi = temp[cur_dir] # 找到了新的边界点,更新 boundary.append(pi) # 加入边界列表 dir = cur_dir # 更新dir为搜索到该点时的方向 if len(boundary) > 2 : initFlag = False # 当边界列表坐标点个数大于2时,才进入算法终止条件判断 # 顺时针输出,即倒序输出边界点的坐标并将输出图像的边缘像素点置1 for point in reversed(boundary): print(point) res_img[point] = 1 return res_img -
测试: 用Nike的logo图像做测试
if __name__ == '__main__': # 边界追踪测试 srcImg = cv.imread("./resource/nike_logo.jpg") res_img = boundary_tracking(srcImg) plt.subplot(211), plt.imshow(srcImg) plt.title('Original Img') plt.subplot(212), plt.imshow(res_img, cmap=plt.cm.gray) plt.title('Detected Boundary in GrayScale') plt.show()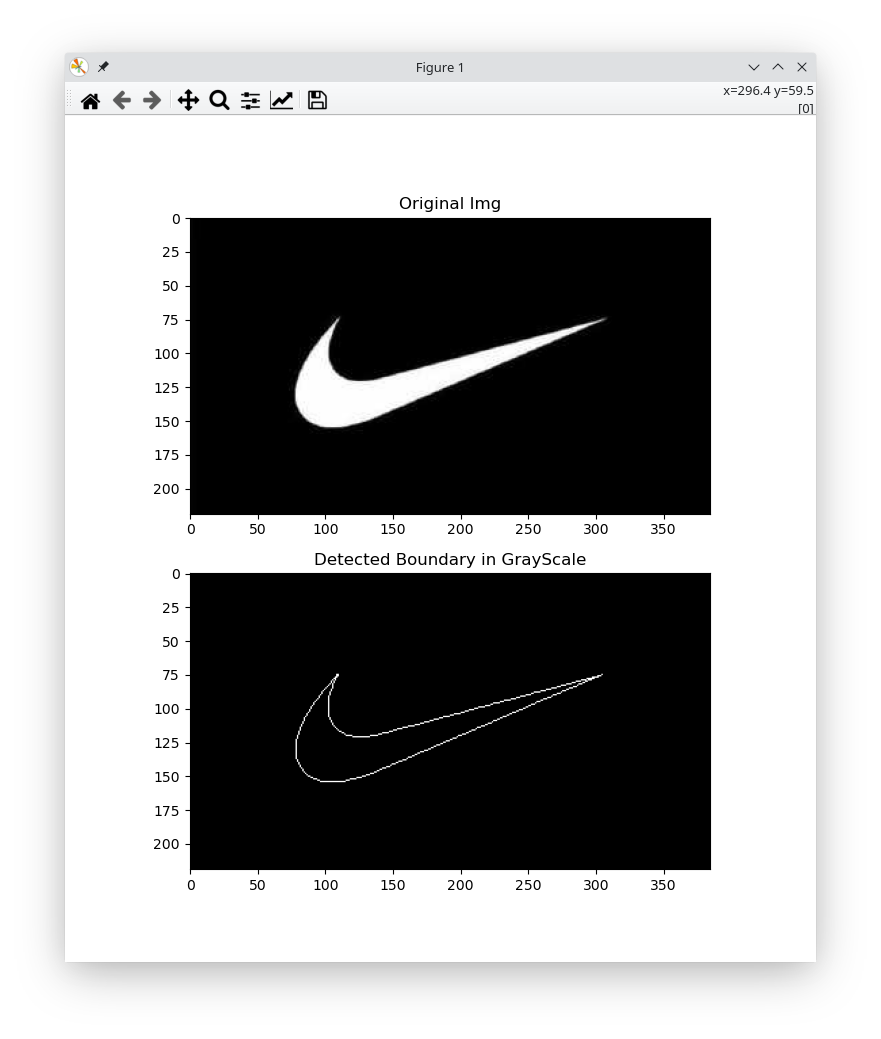
- 描述:
该图像中只有一个白色区域,提取该区域的外围轮廓就可以采用边界跟踪算法,按照许老师的讲解,以逆时针方向进行边界跟踪算法依次找到边界点,最后倒序输出就达到了以顺时针顺序输出坐标的目的