推荐系统
Embedding
Embedding是用一个数值向量表示一个对象的方法,这个对象可以是一个词、一个物品也可以是一部电影。之所以能用向量表示物品,是因为这个向量与其他物品向量之间的距离可以反映这些物品的相似性,即两个向量间的距离向量可以反映他们之间的关系。
Google的著名论文Word2vec中提出了Embedding的经典方法,利用Word2vec模型将单词映射到高维空间中。词向量之间的运算可以揭示词之间的关系,比如:
\[Embedding(Woman) = Embedding(Man) + [Embedding(Queen) - Embedding(King)]\]即从man到woman的向量和从king到queen的向量,在高维空间中其方向和尺度都异常接近。
那么推荐系统中何以用到Embedding技术呢?既然Embedding技术可以揭示向量之间的关系,那么在电影推荐系统中,如果将电影和用户映射到Embedding空间后,就可以通过找出某一用户周围的电影向量,将这些电影推荐给用户即可。
Embedding技术在特征工程中的重要性
处理稀疏特征
在传统特征工程中,因为推荐场景下的类别、ID类特征尤其多,大量使用One-hot编码会导致样本特征向量极度稀疏,而深度学习的结构特点又不利于稀疏特征向量的处理,因此较为成熟的深度学习推荐模型都会使用Embedding层将稀疏高维特征向量转换为稠密低维特征向量。
融合基本特征
从上述对Embedding的介绍中可以发现,相比由原始信息直接处理得到的特征向量,Embedding的表达能力更强。Embedding几乎可以引入任何信息进行编码,使其本身融合大量的信息,即Embedding技术是一种可以通过融合大量基本特征从而生成高阶特征向量的有效手段。
Word2vec
Google的Word2vec即“word to vector”,即将词表达为向量。
想要训练Word2vec模型,需要准备由一组句子组成的语料库。假设一个长度为T的句子其包含的词为$w_1,w_2,…,w_t$,假定每个词都与其相邻词关系最密切。
Word2vec将模型分为两种形式:
CBOW
CBOW模型假设句子中每个词的选取都由相邻的词来决定,即CBOW模型的输入是$w_t$周边的词(不含$w_t$),预测输出则为$w_t$。
Skip-gram
Skip-gram模型与CBOW模型相反,它鸡舍句子中的每个词都决定了相邻词的选取。该模型中的输入是$w_t$,而预测输出则为w~t~周边的词。Skip-gram模型通常更适用于推荐系统,因为为某个用户生成推荐列表时往往只有用户某一特征向量作为输入,要根据该向量找到其周边的向量。
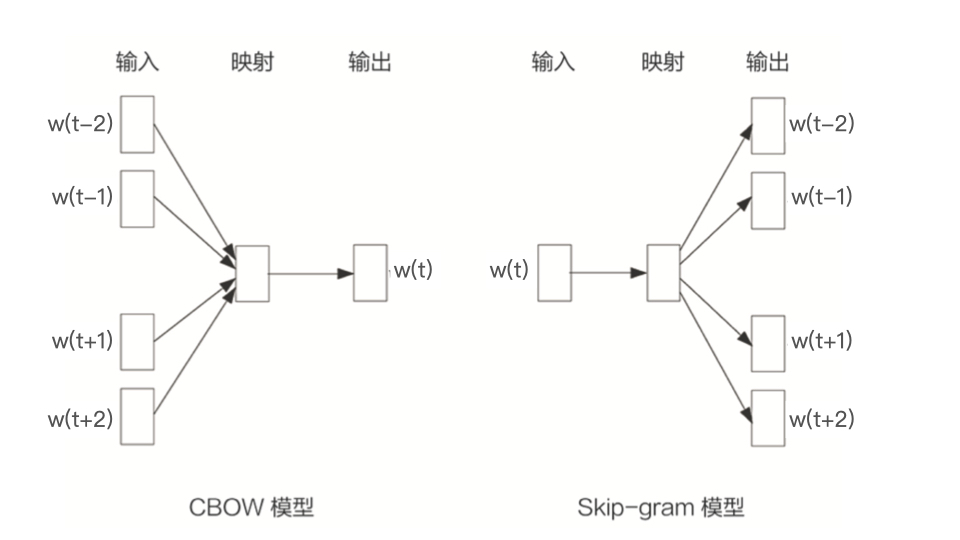
生成Word2vec样本
Word2vec最初应用于NLP领域,训练样本来自于语料库。
样本生成方法: 从语料库中抽取一个句子,选取一个长度为$2c+1$的滑动窗口,将该窗口在句子上从左向右滑动,中心词每改变一次,这个滑动窗口中的词组就形成了一个训练样本。在Skip-gram模型中,中心词决定了其相邻词,则该训练样本定义了输入与输出。 例子:
\[\color{red}Embedding \color{black}| \color{red}技术 \color{black}|在| \color{red}深度学习 \color{black}| \color{red}推荐系统 \color{black}|中|的|\color{red}可用性 \\ \color{black}去除介词和分词 \\ 选取大小为3的滑动窗口在该句子上滑动,生成适用于Skip-gram模型的训练样本 \\ \begin{alignedat}{2} Sample1: & 技术 & \to & Embedding,深度学习 \\ Sample2: & 深度学习 & \to & 技术,推荐系统 \\ Sample3: & 推荐系统 & \to &深度学习,可用性 \end{alignedat}\]Word2vec的模型结构
根据Google论文中的Word2vec模型结构,可以发现其本质是一个三层的神经网络。
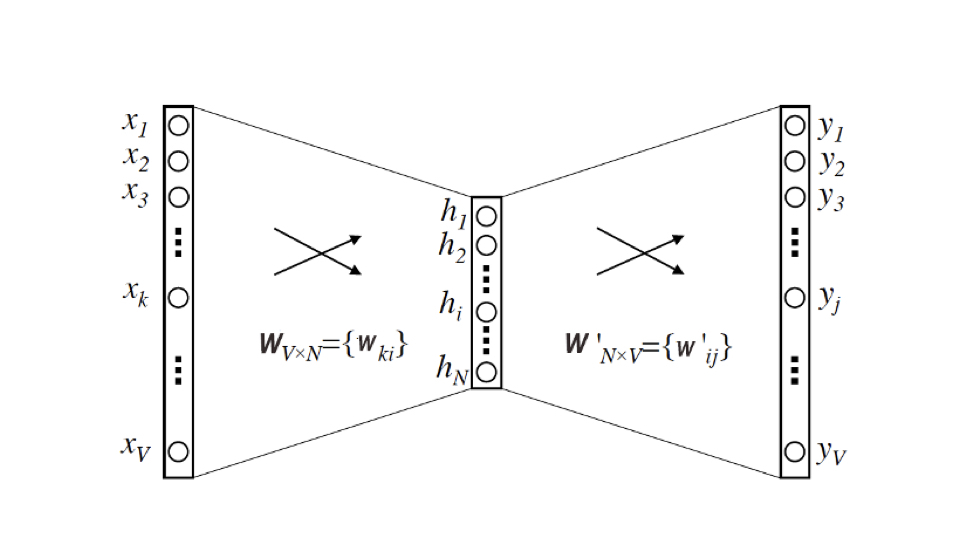
输入层与输出层的维度都是语料库词典大小V。使用上一节中生成的训练样本,这里的输入层就是将中心词转换为One-hot编码后的特征向量作为输入,输出层则输出相邻词转换为Multi-hot编码的特征向量。即基于Skip-gram的Word2vec解决的是一个多分类问题。
中间的隐含层维度为N,N即调参大师负责的工作。炼丹大师需要对模型的效果和复杂度进行权衡,且最终每个词其对应的Embedding向量的维度也由N来决定。
注意隐含层没有使用激活函数,输出层采用Softmax作为激活函数。
这个神经网络最终是要表达从输入向量到输出向量的一个条件概率关系:
\[p(w_O \mid w_I) = \frac{exp(v'_{w_O}v_{w_I})}{\sum_{i=1}^{V}exp(v_{w_i}^{'\top}v_{w_I})}\]使用极大似然估计最大化该条件概率,能够让相似的词向量的内积距离更接近。损失函数与梯度下降另见博文(等我开始学花书再写蛤蛤)。
提取词对应的Embedding向量
上一节中描述了Word2vec的神经网络,那么如何提取每个词对应的Embedding向量呢?前面提到的维度为N的隐含层,这个N其实就是Embedding向量的维度
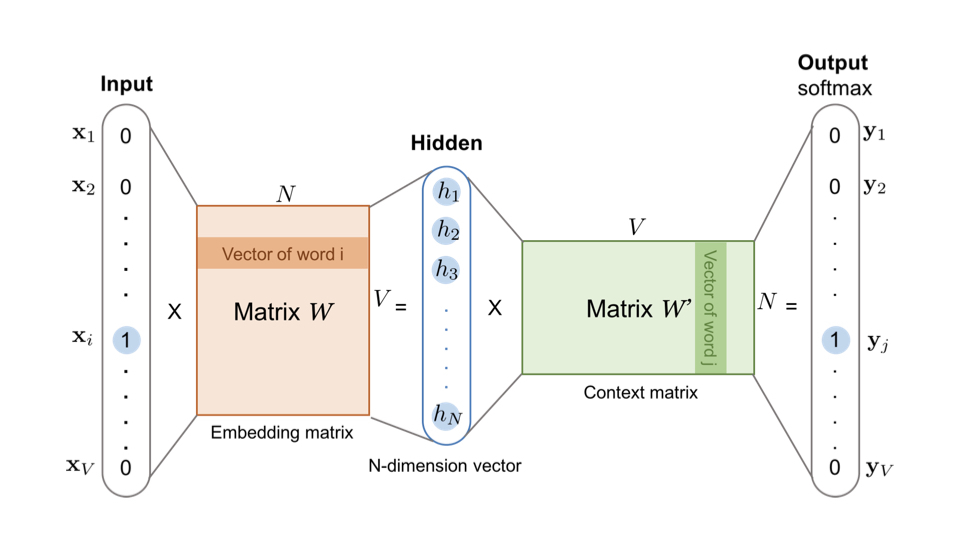
上图中的Embedding Matrix即输入向量矩阵$W_{V \times N}$,该矩阵的每一个行向量就是目标词向量。比如语料库词典中第i个词对应的Embedding,其输入向量由于采用One-hot编码,该输入向量的第i维就应该是1,则$W_{V \times N}$中第i行的行向量就是第i个词对应的Embedding。
应用于推荐系统中时,可以把输入向量矩阵转换成词向量查找表。比如当$V=10000 \space N=300$时,权重矩阵$W_{V \times N}$为10000 X 300维,将其转换为词向量查找表后,每行的权重成为对应词的Embedding向量。将该查找表存储到推荐系统使用的线上数据库中,就可以在计算推荐列表的过程中快速使用Embedding去计算相似性等重要特征。
Item2Vec
NLP领域的Word2vec处理的是句子中的词“序列”,如果将用户观看电影的行为记录作为一个“序列”,根据Word2vec训练的原理,这种序列也可以使用Embedding技术。微软于2015年提出Item2Vec方法,推广Word2vec,使Embedding方法适用于几乎所有的序列数据,不同的地方只在于要使用“序列”的形式将要表达的对象表示出来,仿佛成了一个“句子”,再将其输入Word2vec模型,就可以得到该序列中任一物品的Embedding向量。
对于推荐系统而言,Item2Vec可以利用物品的Embedding直接求得它们的相似性,或者将其作为特征输入推荐模型进行训练。
Graph Embedding
能够被序列表示的物品几乎都可以使用Item2vec方法训练出Embedding,然而真实的互联网是浩如烟海的,通过图结构展现数据更为恰当,比如社交关系图、知识图谱、行为关系图等。
-
社交关系图是社交网络的抽象,通过分析意见领袖结点就可以发现社区,进而根据社区特性进行社交化推荐。
-
知识图谱中包含了不同类型的知识主体及附着在其上的属性(比如人物描述,物品特点)和主体与主体之间、主体与属性之间的关系。
-
行为关系图几乎存在与所有互联网应用中,其本质就是用户与物品的二部图,用户和物品之间的相互行为生成了行为关系图。
如果能将这些重要的图数据Embedding化,就可以生成有价值的特征向量,这就要用到基于图数据的Graph Embedding方法
DeepWalk:基于随机游走
DeepWalk于2014年由美国石溪大学研究者提出,主要思想是在由物品组成的图结构上进行随机游走,产生大量物品序列,并将这些序列作为训练样本最终便可得到物品的Embedding。DeepWalk可看作过渡序列Embedding和Graph Embedding的一种过渡方法。
\[\begin{aligned} U_1 :& \# & \# & D & A & B & \# \\ U_2 :& B & E & \# & D & E & F \\ U_3 :& E & C & B & \# & B & A \end{aligned}\]对于原始用户行为序列,比如购买物品序列、观看视频序列,用这些Item构建物品关系图。比如用户$U_i$先后购买了物品A和B,就在图中增加一条由A到B的有向边,如果后续产生了多条相同有向边,则表征为加强该有向边的权重。如此这般扫描所有用户行为序列后,全局物品关系图就这样建立了起来。
既然DeepWalk是基于随机游走的,那么在生成物品关系图后随即选择起始点,重新产生物品序列。这个过程中,随机游走采样的次数、长度都属于超参数($Hyper \space Parameter$),是给我们调参侠根据具体应用进行调整的部分。
基于随机游走生成物品序列后将其输入Word2vec模型,生成最终的物品Embedding向量。
这里面需要定义的只有每次随机选择起始点的跳转概率,即到达节点$v_i$后,下一步遍历$v_i$的邻接节点$v_j$的概率。由于上述生成的物品关系图是个带权有向图,那么从$v_i$跳转到$v_j$的概率$P(v_j \mid v_i)$的定义如下:
\[P(v_j \mid v_i) = \begin{cases} \frac{\omega_{ij}}{\sum_{v_k \in N_+(V_i)} \omega_{ik}}, & v_j \in N_+(v_i) \\ 0, & e_{ij} \notin \varepsilon \end{cases}\]其中,$N_+(v_i)$为节点$v_i$所有出边的集合,$\omega_{ij}$即节点$v_i$到$v_j$的权重。DeepWalk的跳转概率就是跳转边权重占源点所有出边权重之和的比例。当物品关系图为无向无权图时,权重$\omega_{ij}$固定为1,且$N_+(v_i)$退化为$N(v_i)$。
Node2vec:基于同质性与结构性权衡
Node2vec于2016年由Stanford研究人员基于DeepWalk提出。它主要调整了随机游走跳转概率的方法,使Graph Embedding的结果在网络的同质性($Homophily$)和结构性($Structure Equivalence$)中进行权衡,进一步将不同的Embedding输入推荐模型,使推荐系统能够学习到不同的网络结构特点。
-
同质性:距离上相近的节点的Embedding应该尽量近似。比如与节点$u$邻接的节点$s_1,s_2,s_3$的Embedding表达应该接近以体现网络的“同质性”。在电影平台中,同质性的物品可能是同类别、同一主演或者是同档期上映的电影。
-
结构性:结构上相似的节点的Embedding应该尽量近似。比如前述节点$u$有3个邻接节点,在这个大型网络的其他局部区域也有一个节点$v$,其亦有3个邻接节点。节点$u$和$v$在各自局部网络中结构相似,那么它们的Embedding表达也应该近似以体现网络的“结构性”。在电影平台中,结构性相似的物品可能是各类别中评分最佳或者票房最高的电影。
DeepWalk中随机游走的过程只基于概率而不具倾向性,现在为了表达同质性与结构性,就需要控制跳转的倾向性。
-
为了表达同质性,随机游走方法要倾向于DFS,这样多次跳转后,游走到互相邻接的远方节点上。由于DFS是在一个连通分量上进行的,即基于DFS的随机游走会在一个集团或者社区内部进行,这一“同质性”网络的内部节点的Embedding就更为相似。
-
为了表达结构性,随机游走方法要倾向于BFS,由于BFS是在当前队头节点的邻域中进行,即每次扫描当前节点的局部网络结构,进而分析出当前节点是“局部网络中心节点”或“边缘节点”等,据此生成的序列包含不同节点数量和次序,可以让Embedding抓取到更多结构性信息。
Node2vec通过控制节点间跳转概率以实现倾向性控制
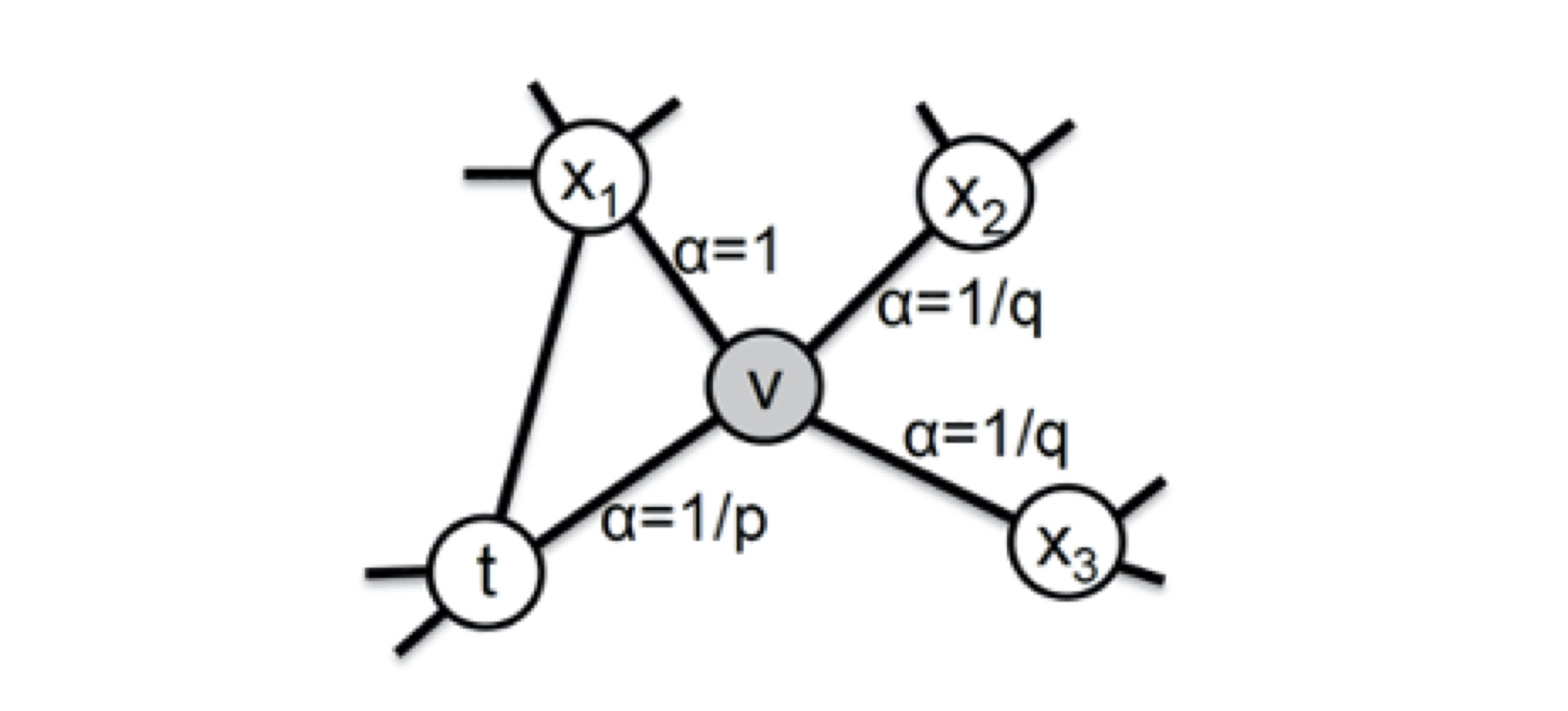
上图中,从节点$t$跳转到节点$v$后,下一步就要具体定义从节点$v$跳转到其某个邻接节点$x_i$的概率。注意,图中$x_1$不仅是当前节点$v$的邻接节点,它还是随机游走过程中上一步访问的节点$t$的邻接节点,而$x_2,x_3$仅与$v$相连。这些不同的特点决定了下一次跳转的概率。
-
从节点$v$跳转到下一个节点$x$的概率,式中$\omega_{vx}$是边$\langle v,x \rangle $的原始权重:
\[\pi_{vx} = \alpha_{pq}(t,x) \cdot \omega_{vx}\] -
上式中,$\alpha_{pq}(t,x)$是Node2vec定义的一个跳转权重,为了倾向同质性或结构性就要分别倾向于BFS或DFS,这个倾向性与该跳转权重有关:
\[\alpha_{pq}(t,x) = \begin{cases} \frac{1}{p} &if \space d_{tx} = 0 \\ 1 &if \space d_{tx} = 1 \\ \frac{1}{q} &if \space d_{tx} = 2 \end{cases}\]$d_{tx}$指节点$t$到节点$x$的距离。这里的距离不是指边$\langle t, x \rangle$的权重,只是一个枚举值。比如$x_1$与$t$相连,则$d_{tx} = 1$;节点$t$到自身的距离定义为$d_{tt} = 0$;对于不与$t$邻接的节点$x_2,x_3$,其$d_{tx_i} = 2$。
另外,式中的参数$p$和$q$共同控制随机游走的倾向性:
-
$p$为返回参数(Return Parameter):$p$越小,则$\frac{1}{p}$越大,即下一步跳转回到节点$t$的概率更大,此时游走过程就更倾向于BFS,仿佛是在遍历节点$t$的所有邻接节点,注重结构性。
-
$q$为进出参数(In-Out Parameter):$q$越小,则$\frac{1}{q}$越大,即下一步跳转到远方节点的概率更大,此时倾向于DFS,注重同质性。
通过调整参数$p$和$q$,就可以产生不同的Embedding结果。
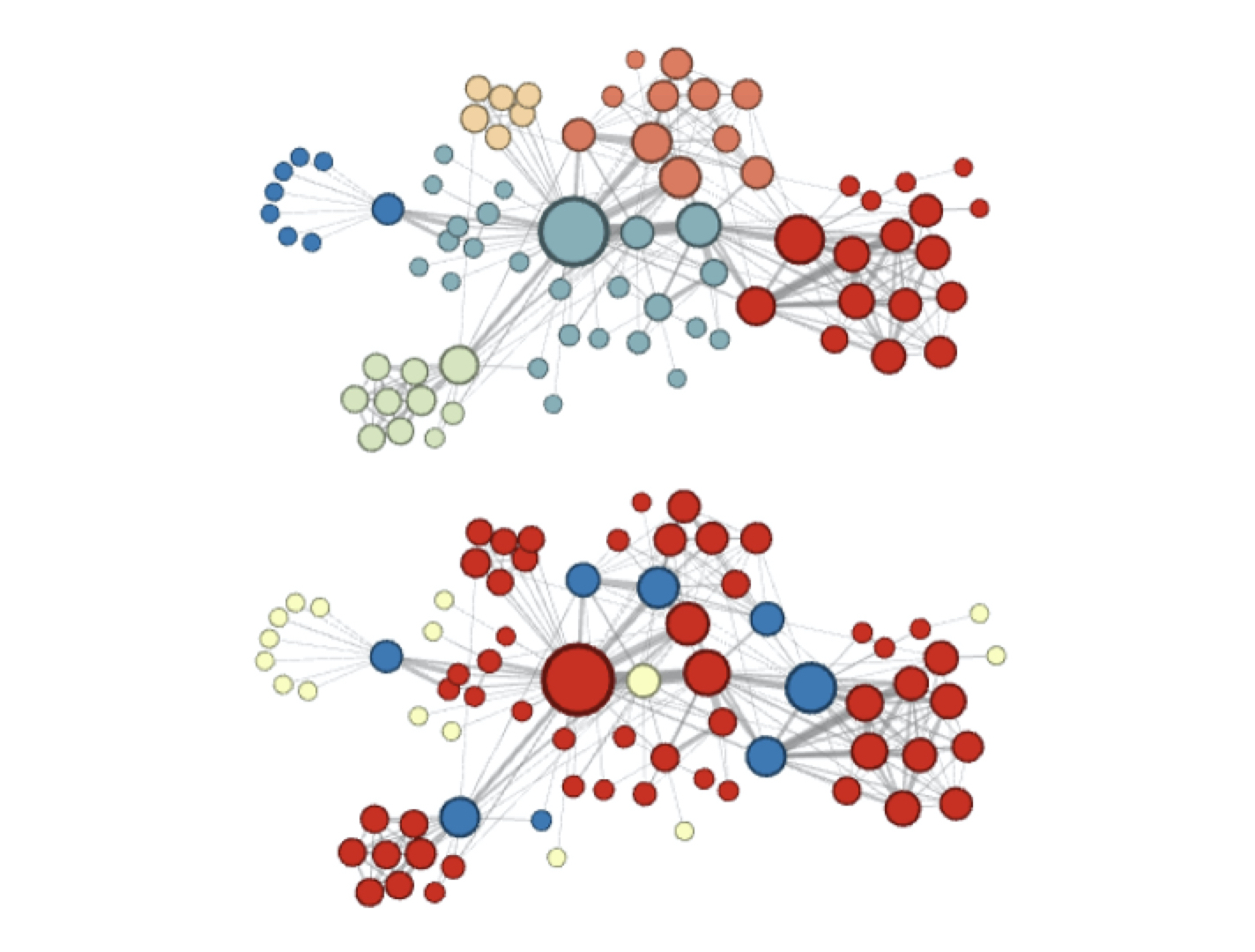
图中上半部分为使用Node2vec时更注重同质性的体现,距离想进的节点颜色更为接近。而下半部分则是注重结构性的体现,结构特点相近的节点其颜色更为接近。
在推荐系统中可以应用Node2vec在同质性和结构性倾向上的不同Embedding结果,发掘物品关系图中的不同特征,以输入深度学习网络。
-
应用Embedding
对于电影推荐系统而言,Item序列即电影的序列。
通常电影平台是通过用户的观影序列,为其生成推荐列表。而MovieLens数据集并不包含用户的观影序列,它只记录了用户对电影进行评分的行为,并存放于ratings.csv中。即现在我要做的是将用户的评分行为生成Embedding,并根据当前电影的Embedding与其他电影的Embedding向量计算相似度,生成相关电影列表。
这里以用户评价过的电影为例,每个用户给电影打分,分值分布在$[0, 5]$之间,而用户给电影评价是有时间顺序的,即一个用户评价过的电影形成了一个序列。
数据集ratings.csv格式
\[\begin{array}{|c|c|c|c|} \hline \text{userId} & \text{movieId} & \text{rating} & \text{timestamp} \\ \hline 1 & 2 & 3.5 & 1112486027 \\ \hline 1 & 29 & 3.5 & 1112484676 \\ \hline 2 & 3 & 4.0 & 974820889 \\ \hline \cdots & \cdots & \cdots & \cdots \\ \hline \end{array}\]使用pyspark处理ratings.csv
Item2vec的基础方法
注意,这里使用了pyspark.sql过滤掉每个用户其评分较低的电影,再将其评分过的电影按照评分时间戳排序。 过滤评分较低的电影原因是为了让Item2vec模型学习到评分较高电影间的相似性,则此时先排除评分较低的电影(生成推荐列表时其实最好也是推荐评分较高的其他电影)。
def sortF(movie_list, timestamp_list):
"""
Sort by timestamp then return the corresponding movie sequence
:param movie_list: [1,2,3]
:param timestamp_list: [123456,12345,10000]
:return: [3,2,1]
"""
# 存放(movie, timestamp)形式的tuple列表
pairs = []
for m, t in zip(movie_list, timestamp_list):
pairs.append((m, t))
# 根据timestamp排序,使用sorted(),排序键选择tuple中的第二个元素,即x[1]
# 默认ASC升序排序,也可以追加参数reverse=true以降序排序
pairs = sorted(pairs, key=lambda x: x[1])
# 根据时间排序后,只返回电影id的序列
return [x[0] for x in pairs]
# 根据Item2vec的思想,将电影评价转换为Item Sequence,尔后交给Word2vec模型进行训练
# Item2vec要学习到物品之间的相似性,根据应用上下文,这里仅过滤评分较高的电影,以学习他们的相似性
def processItemSequence(spark, rawSampleDataPath):
# rating data from rawSampleDataPath
ratingSamples = spark.read.format("csv").option("header", "true").load(rawSampleDataPath)
# ratingSamples.show(5)
# ratingSamples.printSchema()
# udf:User defined function,实现一个用户定义的操作函数,用于之后Spark处理数据集时排序元数据使用
sortUdf = udf(sortF, ArrayType(StringType()))
# pyspark.sql,类sql写法
# 按照用户id分组,过滤掉3.5/5分以下的电影,并在聚集函数中使用UDF对同一用户组的电影评价按时间进行排序(聚集函数默认会在DataFrame中新增一列)
# 返回的是排序好的movieIds(顺序存放movieId的列表,在DataFrame中新增一列,名为movieIds)
# 最后使用withColumn新增一列,列名为movieIdStr,其内容为取movieIds列中列表的各id分量以空格为分界符连接为一个String
userSeq = ratingSamples \
.where(F.col("rating") >= 3.5) \
.groupBy("userId") \
.agg(sortUdf(F.collect_list("movieId"), F.collect_list("timestamp")).alias('movieIds')) \
.withColumn("movieIdStr", array_join(F.col("movieIds"), " "))
userSeq.show()
# rdd is Resilient Distributed Dataset
return userSeq.select("movieIdStr").rdd.map(lambda x: x[0].split(' '))
# 生成的Item序列(User Rated Movie Sequence)
# 最后只用到了第三列"movieIdStr"的内容
+------+--------------------+--------------------+
|userId| movieIds| movieIdStr|
+------+--------------------+--------------------+
| 10096| [858, 50, 593, 457]| 858 50 593 457|
| 10351|[1, 25, 32, 6, 60...|1 25 32 6 608 52 ...|
| 10436|[661, 107, 60, 1,...|661 107 60 1 919 ...|
| 1090|[356, 597, 919, 986]| 356 597 919 986|
| 11078|[232, 20, 296, 59...|232 20 296 593 45...|
| 11332| [589, 32]| 589 32|
| 11563|[382, 147, 782, 7...|382 147 782 73 85...|
| 1159|[111, 965, 50, 15...|111 965 50 154 22...|
| 11722|[161, 480, 589, 3...|161 480 589 364 1...|
| 11888|[296, 380, 344, 5...|296 380 344 588 5...|
| 12529|[902, 318, 858, 3...|902 318 858 356 5...|
| 12847|[296, 590, 588, 3...|296 590 588 318 5...|
| 13192|[527, 858, 750, 2...|527 858 750 293 2...|
| 13282|[596, 661, 783, 9...|596 661 783 903 9...|
| 13442|[593, 778, 296, 288]| 593 778 296 288|
| 13610|[541, 32, 589, 26...|541 32 589 260 29...|
| 13772|[318, 527, 296, 1...|318 527 296 17 59...|
| 13865|[380, 165, 457, 2...|380 165 457 292 3...|
| 14157|[858, 593, 260, 2...|858 593 260 296 1...|
| 14204|[296, 349, 316, 3...|296 349 316 318 3...|
+------+--------------------+--------------------+
only showing top 20 rows
得到Item Sequence后,下一步就是将其作为训练样本送入Word2vec模型进行训练,目标是得到各电影的Embedding向量。
使用pyspark.mllib.feature里的Word2vec模型
from pyspark.mllib.feature import Word2Vec
# 使用Word2vec模型训练得到Item2vec的Embedding向量
def trainItem2vec(spark, samples, embLength, embOutputPath, redisKeyPrefix, saveToRedis=False):
# 构造Word2vec网络模型结构
# setVectorSize设置Embedding向量的维度,即Word2vec的隐含层的神经元数目
# setWindowSize设置在序列上进行滑动的滑动窗口大小(windowSize=2c+1)
# setNumIterations设置训练模型时的迭代次数,类似epoch
word2vec = Word2Vec().setVectorSize(embLength).setWindowSize(5).setNumIterations(10)
model = word2vec.fit(samples)
# 调用封装好的函数寻找与某个item最相似的N个其它item
# 这里是用余弦相似度计算的相似性,其它相似性计算方法见我的另一篇博文
synonyms = model.findSynonyms("592", 20) # id"592"为蝙蝠侠Batman
for synonym, cosineSimilarity in synonyms:
print(synonym, cosineSimilarity)
# 准备从训练完毕后的Word2vec中取出Embedding向量并存入目标文件夹中或redis中
embOutputDir = '/'.join(embOutputPath.split('/')[:-1]) #
if not os.path.exists(embOutputDir):
os.mkdir(embOutputDir)
# 使用getVectors()方法得到存放word及其向量表达(Embedding向量,W_vxn的行向量)的map<movie_id : String, Embedding : Vector>
with open(embOutputPath, 'w') as file:
for movie_id in model.getVectors():
vectors = " ".join([str(emb) for emb in model.getVectors()[movie_id]])
file.write(movie_id + ":" + vectors + "\n")
# TODO: embeddingLSH(spark, model.getVectors())
return model
与ID为”592”的电影《Batman》最为相似的前20部电影,以余弦相似度降序排序
380 0.9233925938606262
150 0.893817663192749
590 0.8740843534469604
165 0.8195751905441284
153 0.8143924474716187
349 0.8027638792991638
588 0.788188099861145
457 0.7476001381874084
344 0.714634358882904
480 0.7013552188873291
316 0.6817461252212524
595 0.6664051413536072
296 0.6509096026420593
589 0.6373887658119202
329 0.61918044090271
318 0.611433744430542
356 0.5735329389572144
1 0.537996768951416
110 0.5199078917503357
593 0.5167772769927979
当然,这里只是使用spark自带的函数显示相似电影的一个demo。在推荐系统的实现中(比如我的毕业设计:Cinema Chain Platform),需要从数据库取出Embedding向量后,自行计算与其他电影Embedding向量的余弦相似度并生成推荐列表。
Graph Embedding
使用Deep Walk进行简单实现
在Deep Walk的概念中,最重要的是求出从某节点跳转到其各个邻接节点的概率,则要求出转移概率矩阵
'''
Graph Embedding
使用Deep Walk的简单实现
依据Deep Walk原理,要准备Item之间的概率转移矩阵,即图中到达某节点后,根据其出边权重和计算的跳转到各邻接节点的概率
'''
# 根据输入的Item序列,将其中元素两两结合生成相邻的Item Pair
def generate_pair(x):
# eg
# input x as Seq: [50, 120, 100, 240] List[str]
# output pairSeq: [(50, 120), (120, 100), (100, 240)] List[Tuple(str, str)]
pairSeq = []
previous_item = ''
for item in x:
if not previous_item:
previous_item = item
else:
pairSeq.append((previous_item, item))
previous_item = item
return pairSeq
"""
生成转移概率矩阵
return transitionMatrix(转移概率矩阵) as defaultdict(dict), itemDistribution
"""
# samples即上一步生成的Item Sequence而不是电影各自的Embedding
def generateTransitionMatrix(samples):
# 使用flatMap将Item序列碎为一个个Item Pair
pairSamples = samples.flatMap(lambda x: generate_pair(x))
# 使用pyspark.rdd.countByValue(), 返回的是存放Item Pair及其出现的次数的dictionary, 即{(v1, v2):2, (v1, v3):4, ...}
# Return the count of each unique value in this RDD as a dictionary of (value, count) pairs.
pairCountMap = pairSamples.countByValue()
# 记录总对数
pairTotalCount = 0
# 转移数量矩阵,双层Map类数据结构.Like Map<String, Map<String, Integer>> in JAVA
transitionCountMatrix = defaultdict(dict)
# 记录从某节点出发,其所有出边的权重之和
itemCountMap = defaultdict(int)
# 统计Item Pair的个数 {tuple(v1, v2):int(count)}
for pair, count in pairCountMap.items():
v1, v2 = pair
transitionCountMatrix[v1][v2] = count
itemCountMap[v1] += count
pairTotalCount += count
# 转移概率矩阵,根据前述辅助变量进行计算
transitionMatrix = defaultdict(dict)
itemDistribution = defaultdict(dict)
for v1, transitionMap in transitionCountMatrix.items():
for v2, count in transitionMap.items():
# 从某节点跳转到其某一邻接节点的概率是该边权重占所有出边权重之和的比例
transitionMatrix[v1][v2] = transitionCountMatrix[v1][v2] / itemCountMap[v1]
for v, count in itemCountMap.items():
itemDistribution[v] = count / pairTotalCount
return transitionMatrix, itemDistribution
生成完毕转移概率矩阵后,其实也隐含了Item Graph的图结构,即一个用邻接矩阵描述的Graph,只是不邻接的节点之间在矩阵之中不存在其边对应的0值。下一步就是在这个图中进行随机游走,生成训练样本。
# 单次随机游走
def oneRandomWalk(transitionMatrix, itemDistribution, sampleLength):
sample = []
# 随机选择本次游走的起点
# 产生一个[0,1)间的随机浮点数
randomDouble = random.random()
startItem = ""
accumulateProbability = 0.0
# 朴素方法找起始节点
for item, prob in itemDistribution.items():
accumulateProbability += prob
if accumulateProbability >= randomDouble:
startItem = item
break
sample.append(startItem)
# 标记当前节点的变量
cur_v = startItem
i = 1
while i < sampleLength:
# 如果当前节点没有出边,即本次游走终止(即本次训练样本长度小于最大样本长度)
if (cur_v not in itemDistribution) or (cur_v not in transitionMatrix):
break
next_v_probability = transitionMatrix[cur_v]
# 故技重施
randomDouble = random.random()
accumulateProbability = 0.0
for next_v, probability in next_v_probability.items():
accumulateProbability += probability
if accumulateProbability >= randomDouble:
cur_v = next_v
break
sample.append(cur_v)
i += 1
return sample
# 在图中随机游走生成训练样本
def randomWalk(transitionMatrix, itemDistribution, sampleCount, sampleLength):
samples = []
for i in range(sampleCount):
samples.append(oneRandomWalk(transitionMatrix, itemDistribution, sampleLength))
return samples
仍是将得到的训练样本输入Item2vec进行训练
def graphEmbedding(samples, spark, embLength, embOutputPath, redisKeyPrefix, saveToRedis=False):
# 根据samples(Item Sequence)生成图及其概率转移矩阵和Item的分布情况(某Item作为源点出现在所有节点对中的次数占)
transitionMatrix, itemDistribution = generateTransitionMatrix(samples)
# 先定死样本数量(即游走次数)和每个训练样本的最大长度(生成的训练样本有可能提前终止)
sampleCount = 20000
sampleLength = 10
rawSamples = randomWalk(transitionMatrix, itemDistribution, sampleCount, sampleLength)
# 使用sc.parallelize分发训练样本集形成一个RDD(即创建并行集合)
rddSamples = spark.sparkContext.parallelize(rawSamples)
# 开始训练
trainItem2vec(spark, rddSamples, embLength, embOutputPath, redisKeyPrefix=redisKeyPrefix, saveToRedis=saveToRedis)
使用Graph Embedding后,训练Item2vec后仍显示与电影Batman相似的前20部电影,可以与前述Item2ve基础方法的样例进行比较
380 0.9517624974250793
590 0.9420034289360046
150 0.9202093482017517
349 0.8714569211006165
165 0.8661364316940308
153 0.8209306001663208
780 0.7379775047302246
588 0.7256513833999634
457 0.7177420854568481
296 0.7155550122261047
1 0.7154592275619507
316 0.6954978704452515
344 0.6731524467468262
589 0.6293243765830994
480 0.6050290465354919
595 0.5840312242507935
260 0.5788465738296509
356 0.5788094401359558
318 0.5676533579826355
648 0.5578194856643677
在推荐系统中的蝙蝠侠电影详情页里,我手动标出了各电影在数据集中的movieId,对比上述结果可以直观看到推荐电影与蝙蝠侠的相似度还是比较可靠的
