GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields
摘要 Abstract
深度生成模型使高分辨率逼真图像合成成为了可能,但它仍然不能满足许多应用的需求:可控的内容创作。虽然近几年的工作研究了如何解耦数据变化的潜在因素,但大部分研究仍然在二维空间中进行操作却忽略了我们的世界是三维的事实。此外,只有少数工作考虑了场景的合成性质。我们关键的研究假设就在于将合成3D场景表达并入到生成模型中从而使图像合成更可控。在无监督情景下使用非结构化且未定位姿态的图像集进行学习时,将场景表示为合成神经特征场有助于从背景中解耦出单个或多个物体及它们各自的形状和外观特征。将这种场景表示技术同神经渲染管线相结合便产生了一个快速且真实的图像合成模型。而我们的实验也证明,我们的模型能够解耦出独立对象且允许在场景中对它们执行平移和旋转就像在改变相机姿态一般。
1. 简介 Introduction
生成和处理逼真图像内容一直是计算机视觉和图形学的一个长远目标。现代计算机图形技术取得了令人惊叹的成果,成为了游戏和电影制作的行业标准。然而,这种技术基于昂贵的硬件设备而且需要大量的人力投入进3D内容创作和布局上。
近年来,计算机视觉社区在高仿真图像生成方面取得了长足进步。尤其是生成对抗网络(GAN)成为了一类强大的生成模型。基于12345这些论文,它们能够在高达 $1024^2$ 的分辨率上合成写实图片。
尽管取得了这些成功,逼真2维图像合成却并不是生成模型应用所需的唯一方面。图像生成过程也应该以一种简洁一致的方式可控。为此,许多工作67489101112131415 研究了如何从没有明确监督的数据集中学习解耦表示。解耦的定义不尽相同1617,但一般是指能够在不改变其他属性的情况下控制一种感兴趣的属性比如物体形状、大小或者姿态。然而大多数方法都没有考虑到场景的合成性质且仅在2维空间中进行操作,忽略了我们的三维世界。这通常会导致耦合表示且控制机制不是内置的而是需要在其潜在空间中寻找它的后验。然后,这些特性对于模型的成功应用至关重要,比如需要以一致方式生成复杂对象轨迹的电影制作。
因此,最近的几项工作研究了如何将3D表达(比如体素181920、基元21、辐射场22)直接并入到生成模型中。虽然这些方法通过内置控制取得了令人惊叹的成果,但他们大多仅限于单对象场景,对于更高分辨率、更复杂逼真的图像而言其合成结果不太具有一致性(比如物体不在中心或者背景杂乱的场景)。
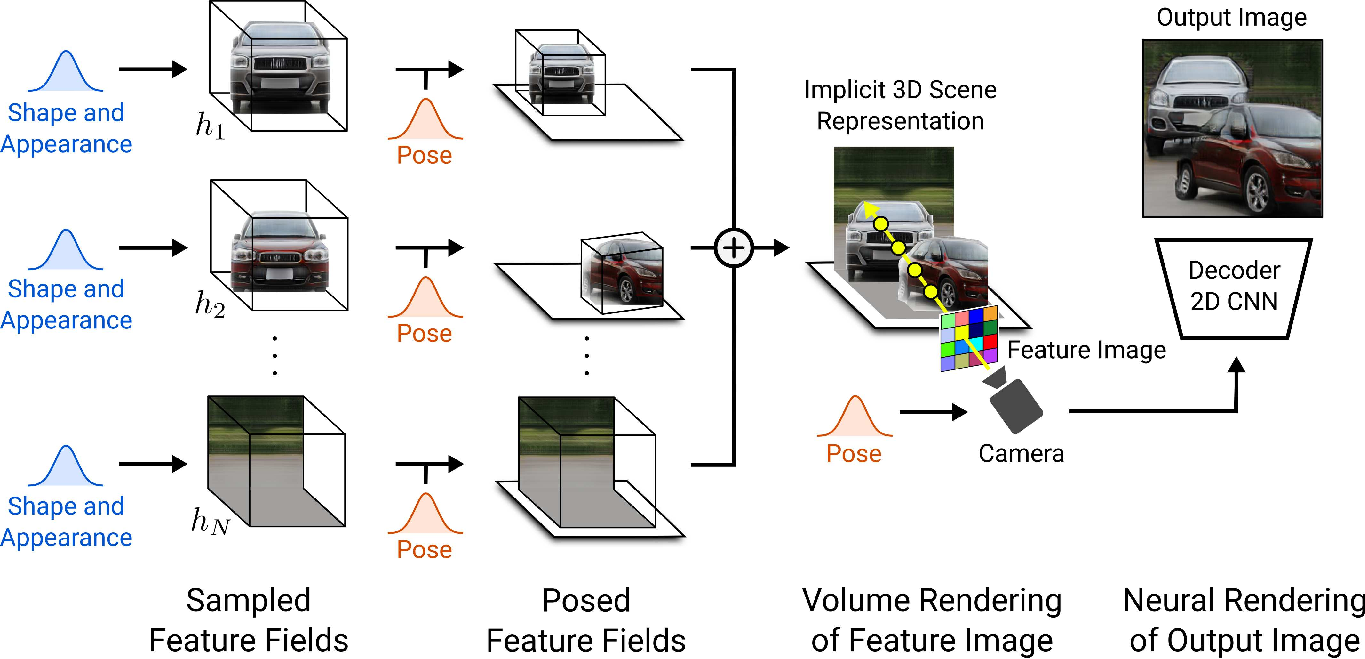
我们的贡献: 在这篇论文中,我们要介绍GIRAFFE,它是一种从原始的非结构化图像数据集中以可控且仿真的方式生成场景的新方法。我们的关键insight由两部分组成:首先,将合成3D场景表示直接并入到生成模型中以实现更可控的图像合成。其次,将这种显式3D表示同神经渲染管线相结合以加速推理及更加逼真的图像合成。为此,我们将场景表达为组合生成式神经特征场,如图1所示。我们将场景体绘制为分辨率相对较低的特征图像以节省时间和计算量。神经渲染器会处理这些特征图像并输出最终的渲染结果。这样,我们的方法实现了高质量的图片生成并扩展到现实世界的场景中。我们发现,基于原始非结构化的图像数据集进行训练后,我们提出的方法同时满足了单对象和多对象场景的可控图片合成。
2. 相关工作 Related Work
基于GAN的图像合成: 生成对抗网络(GAN)23已被一系列研究工作12345证明,其允许以高达$1024^2$的分辨率进行仿真图像合成。为了更好地控制合成过程,有许多工作研究了如何在没有显式监督的情况下解耦变化因素。它们要么修改训练目标6512或网络架构4,要么研究了工程化的预训练生成模型的潜在空间24252627282930。然而,所有的这些工作都没有明确地建模场景的组合性质。因此,最近的工作研究了如何在对象级别上控制合成过程313233343536373839。在取得了逼真合成结果的同时,上述提到的工作都以2D形式建模图像的形成过程而忽略了真实世界的3维结构。在这项工作中,我们提倡直接在3D空间对形成过程进行建模以获得更好的解耦表示和更可控的图像合成。
隐式函数: 使用隐函数进行3D几何表示在基于学习的3维重建领域中越来越受欢迎404142434445464748,并且它们已被扩展到了场景级重建4950515253。为了克服3D监督的需求,一些工作545556576提出了可微分渲染技术。Mildenhall等人58提出了神经辐射场(NeRFs),他们将隐式神经模型与体绘制相结合以产生新的适用于复杂场景的视图合成技术。考虑到它们的极佳表达能力,我们将NeRFs的一种生成式变体作为我们的对象级表示技术。与我们的方法相比,前面所讨论过的工作需要以相机姿态作为监督的多视角图像,每个场景训练一个单一网络并且无法生成新的场景。
3D感知图像合成: 一些工作研究了如何将3D表示作为归纳偏置纳入生成模型中5960616218216319206422。虽然有许多其他方法使用了额外监督6566676869,但我们专注于像我们提出的方法一样在原始图像数据集上进行训练的研究工作。Henzler等人18使用可微分渲染技术学习基于体素的表示。其结果是3D可控的,但是由于立方内存增长所导致的有限体素分辨率使这些结果仍然呈现出了人工痕迹。Nguyen-Phuoc等人1920提出体素化特征网格表示,可以通过一种重塑操作渲染为2D结果。在取得了惊人成果的同时,训练却变得不太稳定,并且对于更高分辨率的合成结果也不太一致。Liao等人21使用了结合基元和可微分渲染的抽象特征。在处理多对象场景时,它们需要难以在真实世界中获得的纯背景图像作为额外的监督形式。Schwarz等人22提出了生成式神经辐射场(GRAF)。虽然它能够在高分辨率下实现可控图像合成,但这种表示方法仅限于单对象场景,在更加复杂的真实世界图像上其效果会变差。相比之下,我们将合成3D场景结构并入到生成模型中,使其能够自然地处理多对象场景。此外,通过集成神经渲染管线技术707172737475577677,我们的模型可以扩展到更加复杂的真实世界数据上。
3. 方法 Method
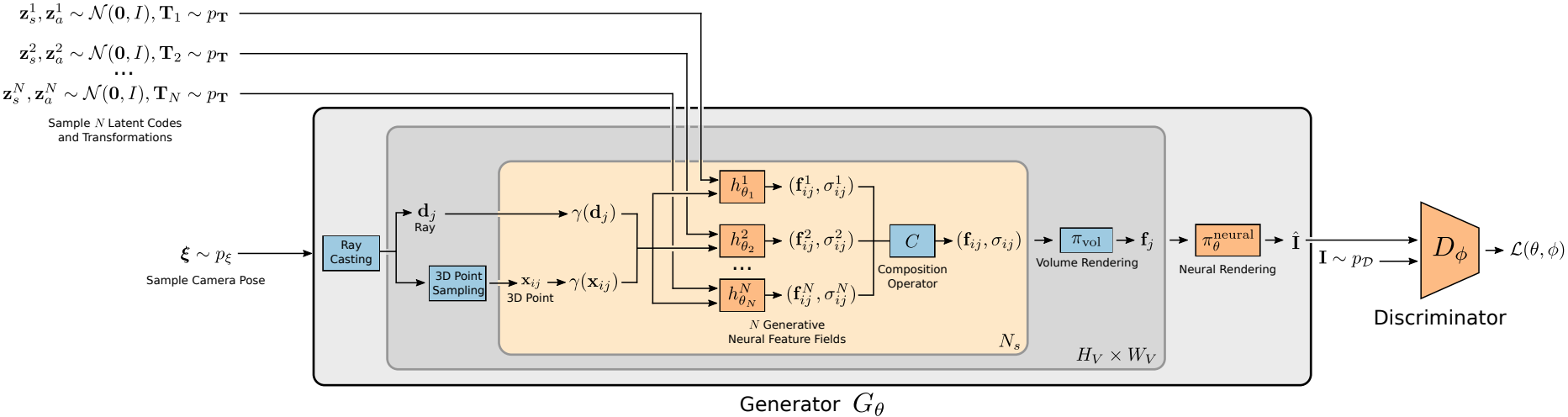
我们的目标是一种可以在没有添加额外监督的原始图像集上进行训练的可控图像合成管线。下面,我们将讨论我们提出的方法的主要组成部分。首先,我们将独立对象建模为神经特征场(3.1节)。接着,我们利用特征场的可加性使用多个独立对象去合成新场景(3.2节)。对于渲染,我们探索了体绘制与神经渲染技术的有效组合方法(3.3节)。最后,我们讨论了如何在原始图像集上训练我们的模型(3.4节)。图3展示了我们所提出方法的全貌。
3.1 使用神经特征场表示对象
神经辐射场: 辐射场是一个将3D点 $\mathbf{x} \in \mathbb{R}^3$ 和视角方向 $\mathbf{d} \in \mathbb{S}^2$ 映射到体积密度$\sigma \in \mathbb{R}^{+}$和RGB颜色值 $\mathbf{c} \in \mathbb{R}^3$ 的连续函数 $f$ 。其他两篇论文5878观察到,当 $f$ 用神经网络参数化时,低维输入 $\mathbf{x}$ 和 $\mathbf{d}$ 需要被映射到高维特征才能够表示复杂信号。更具体地说,需要使用一个预定义的位置编码逐元素地应用到 $\mathbf{x}$ 和 $\mathbf{d}$ 的每个分量上:
\[\gamma(t, L) = \left( \sin(2^{0}t\pi), \cos(2^{0}t\pi), \dots, \sin(2^{L}t\pi), \cos(2^{L}t\pi) \right) \tag{1}\]其中 $t$ 是标量输入,比如 $\mathbf{x}$ 或 $\mathbf{d}$ 的某个分量,而 $L$ 是频率倍频程的值。在生成模型的上下文中,我们观察到这种表示方法的额外优势:它引入了归纳偏置来学习规范方向上的3D形状表示,否则其表示的方向一般是任意的。
遵循隐式形状表示方法414347,Mildenhall等人58建议通过使用多层感知机(MLP)参数化 $f$ 来学习神经辐射场(NeRFs):
\[\begin{aligned} f_{\theta}: \mathbb{R}^{L_{\mathbf{x}}} \times \mathbb{R}^{L_{\mathbf{d}}} &\to \mathbb{R}^{+} \times \mathbb{R}^{3} \\ (\gamma(\mathbf{x}), \gamma(\mathbf{d})) &\mapsto (\sigma, \mathbf{c}) \end{aligned} \tag{2}\]其中 $\theta$ 表示网络的参数,$L_{\mathrm{x}},L_{\mathrm{d}}$ 表示位置编码的输出维度。
生成式神经特征场: 上述两篇论文中其中一篇58是将 $\theta$ 拟合到单个场景的多姿态图像上,但是Schwarz等人22提出了一个适用于神经辐射场的生成模型(GRAF),该模型可以在未定位姿态的图像集上进行训练。为了学习NeRFs的隐空间,他们根据形状和外观的隐向量 $\mathrm{z}_s, \mathrm{z}_a \sim \mathcal{N}(0, I)$来调节MLP:
\[\begin{aligned} g_{\theta} : \mathbb{R}^{L_{\mathbf{x}}} \times \mathbb{R}^{L_{\mathbf{d}}} \times \mathbb{R}^{M_s} \times \mathbb{R}^{M_a} &\to \mathbb{R}^{+} \times \mathbb{R}^{3} \\ (\gamma(\mathbf{x}), \gamma(\mathbf{d}), \mathbf{z}_s, \mathbf{z}_a) &\mapsto (\sigma, \mathbf{c}) \end{aligned} \tag{3}\]其中 $M_s, M_a$ 是隐向量的维度数。
在本次工作中,我们探索了更有效地将体积与神经渲染进行组合的方式。我们用更加通用的 $M_f$-维特征 $\mathbf{f}$ 替换GRAF的3维颜色输出 $\mathbf{c}$ ,从而将对象表示为生成式神经特征场(Generative Neural Feature Fields):
\[\begin{aligned} g_{\theta} : \mathbb{R}^{L_{\mathbf{x}}} \times \mathbb{R}^{L_{\mathbf{d}}} \times \mathbb{R}^{M_s} \times \mathbb{R}^{M_a} &\to \mathbb{R}^{+} \times \mathbb{R}^{M_f} \\ (\gamma(\mathbf{x}), \gamma(\mathbf{d}), \mathbf{z}_s, \mathbf{z}_a) &\mapsto (\sigma, \mathbf{f}) \end{aligned} \tag{4}\]对象表示: NeRF和GRAF的主要局限之处在于其整个场景是由单个模型进行表示。由于我们对解耦场景中的不同实体更感兴趣,我们需要控制独立对象(我们将背景也视为一个对象)的姿态、形状和外观。因此,我们针对每个对象使用结合了仿射变换的分离特征场去分别表示他们
\[\mathbf{T} = \{ \mathbf{s}, \mathbf{t}, \mathbf{R} \} \tag{5}\]其中 $\mathbf{s}, \mathbf{t} \in \mathbb{R}^3$ 表示尺度和平移参数,$\mathbf{R} \in SO(3)$ 表示旋转矩阵。通过这种表示方法,我们将对象上的点转换到了场景空间,如下所示:
\[k(\mathbf{x})= \mathbf{R} \cdot \begin{bmatrix} s_1 & & \\ & s_2 & \\ & & s_3 \\ \end{bmatrix} \cdot \mathbf{x} + \mathbf{t} \tag{6}\]在实践中,我们在场景空间中进行体绘制并评估其规范对象空间中的特征场(如图1所示):
\[(\sigma, \mathbf{f}) = h_{\theta}(\gamma(k^{-1}(\mathbf{x})), \gamma(k^{-1}(\mathbf{d})), \mathbf{z}_s, \mathbf{z}_a) \tag{7}\]这种方式允许我们在一个场景中排布多个对象。所有的对象特征场共享它们的权重,并且 $\mathbf{T}$ 是从一个依赖于数据集的分布中进行采样得到的(见3.4节)。
3.2 场景合成
根据上述讨论,我们将场景描述为 $N$ 个实体的组合,其中前 $N-1$ 个是场景中的对象,最后一个代表背景。
考虑两种情况:其一,$N$ 在整个数据集上是固定的,这样图像总是包含 $N-1$ 个对象再加上其背景。其二,$N$ 在整个数据集中会产生变化。在实践中,我们对背景使用与对象相同的表示方式,但是要固定尺度和平移参数 $\mathbf{s}_N, \mathbf{t}_N$ 使背景覆盖整个场景,并且要设置场景空间原点为其中心。
合成算子: 为了定义合成算子 $C$ ,让我们回想一下:一个单一实体的特征场 $h_{\theta_{i}}^{i}$ 将根据给定点 $\mathbf{x}$ 和视角方向 $\mathbf{d}$ 去预测体积密度 $\sigma \in \mathbb{R}^{+}$ 和特征向量 $\mathbf{f}_i \in \mathbb{R}^{M_f}$ 。当组合非固体对象时,处理点 $\mathbf{x}$ 处整体密度的一个自然而然的选择79是将各个密度累加并且使用密度加权平均值去组合位于 $(\mathbf{x}, \mathbf{d})$ 处的所有特征:
\[C(\mathbf{x}, \mathbf{d}) = \left( \sigma, \frac{1}{\sigma}\sum_{i=1}^{N}\sigma_{i}\mathbf{f}_{i} \right), ~~\textrm{where}~~\sigma = \sum_{i=1}^{N}\sigma_{i} \tag{8}\]这种对于算子 $C$ 的选择不仅简单直观,它还有额外的优势:确保梯度流向了所有密度大于0的实体。
3.3 场景渲染
3D体绘制: 前人的研究工作80815822利用体绘制输出了一个RGB值,我们将此公式扩展以渲染一个 $M_f$-维特征向量 $\mathbf{f}$。
对于给定的相机外部参数 ${\xi}$,令 ${\mathbf{x}{j}}{j=1}^{N_s}$ 为给定像素点沿相机射出光线 $\mathbf{d}$ 的各个不同采样点($N_s$为采样点个数),并且令 $(\sigma_{j}, \mathbf{f}j)=C(\mathbf{x}_j, \mathbf{d})$ 为采样点 $\mathbf{x}{j}$ 的特征场对应的体积密度和特征向量。体绘制算子 $\pi_{\textrm{vol}}$ 将这些采样点的评估映射到该像素点的最终特征向量 $\mathbf{f}$:
\[\begin{array}{c} \pi_{\textrm{vol}} : (\mathbb{R}^{+} \times \mathbb{R}^{M_f})^{N_s} \to \mathbb{R}^{M_f} \\ \{ \sigma_{j}, \mathbf{f}_j \}_{j=1}^{N_s} \mapsto \mathbf{f} \end{array} \tag{9}\]可以使用NeRF58中使用的数值积分方法去计算 $\mathbf{f}$:
\[\mathbf{f} = \sum_{j=1}^{N_s}\tau_{j}\alpha_{j}\mathbf{f}_{j}~~~~ \tau_{j} = \prod_{k=1}^{j-1}(1 - \alpha_{k})~~~~ \alpha_{j} = 1 - e^{-\sigma_j\delta_j} \tag{10}\]其中 $\tau_j$ 是透射率,$\alpha_j$ 是 $\mathbf{x}j$ 的alpha值,$\delta_j = |\mathbf{x}{j+1} - \mathbf{x}j |_2$ 是相邻样本点之间的距离。于每个像素点上计算 $\pi{\textrm{vol}}$ 即可得到整个特征图像。为了提高效率,我们以 $16^2$ 的分辨率渲染特征图像,该分辨率低于 $64^2$ 或 $256^2$ 像素点的输出分辨率。接着,我们使用2D神经渲染将低分辨率特征图像上采样为更高分辨率的RGB图像。
2D神经渲染: 神经渲染算子
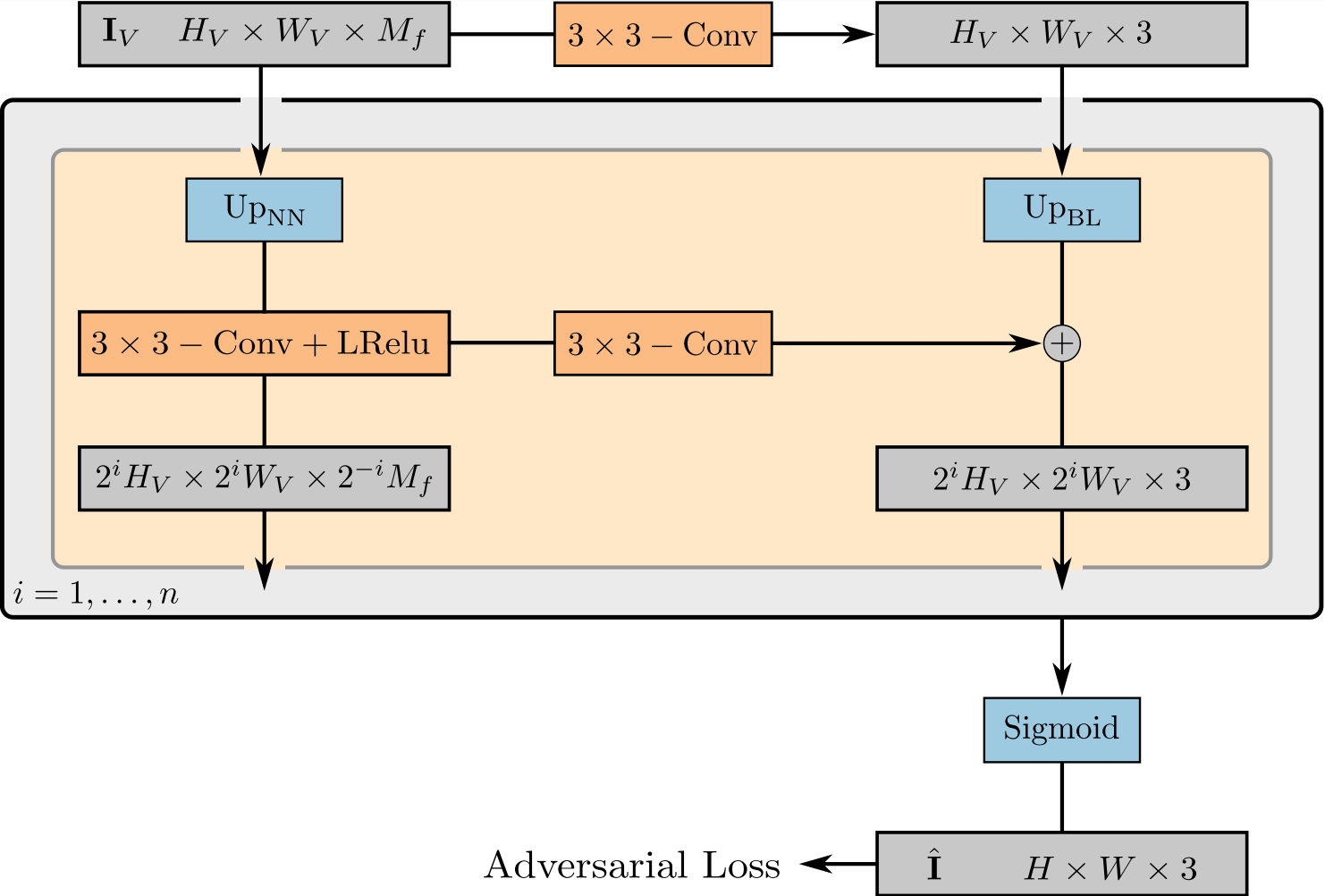
\[\pi_{\theta}^{\textrm{neural}} : \mathbb{R}^{H_V \times W_V \times M_f} \to \mathbb{R}^{H \times W \times 3} \tag{11}\]使用权重 $\theta$ 将特征图像 $\mathbf{I}V \in \mathbb{R}^{H_V \times W_V \times M_f}$ 映射为最终的合成图像 $\hat{\mathbf{I}} \in \mathbb{R}^{H \times W \times 3}$。我们将 $\pi{\theta}^{\textrm{neural}}$ 参数化为使用Leaky ReLU8283作为激活函数的2维卷积神经网络(CNN),并将最近邻上采样与 $3 \times 3$ 卷积相结合以提高空间分辨率,如图4所示。我们选择较小的kernel尺寸且不使用中间层,即仅允许在空间上进行较小的细化以避免在图像合成过程中全局场景属性的耦合问题,同时也可以增加输出分辨率。受StyleGAN改进方法5的启发,我们在每一个空间分辨率上将特征图像映射为一张RGB图片,并通过双线性上采样将前一个空间分辨率上的输出添加到下一个上。这种跳连方式确保了一个流向特征场的强梯度流。通过在最后一个RGB层上应用sigmoid激活函数便可获得我们最终的图像预测 $\hat{\mathbf{I}}$。我们在消融研究中验证了这种设计选择,如表4所示。
\[\begin{array}{c|cccc} \hline Full & -Skip & -Act. & +NN.RGB UP. & +Bi.Feat. UP. \\ \hline \textbf{16.16} & 16.66 & 21.61 & 17.28 & 20.68 \\ \hline \end{array}\]3.4 训练
生成器: 我们将完整的生成过程表示为
\[\begin{array}{c} G_{\theta}(\{ \mathbf{z}_s^i, \mathbf{z}_a^i, \mathbf{T}_i \}_{i=1}^{N}, \mathbf{\xi}) = \pi_{\theta}^{\textrm{neural}}(\mathbf{I}_V) \\ \textrm{where}~~~~\mathbf{I}_V = \{ \pi_{\textrm{vol}} (\{ C(\mathbf{x}_{jk}, \mathbf{d}_k)\}_{j=1}^{N_s} ) \}_{k=1}^{H_V \times W_V} \end{array} \tag{12}\]其中,$N$ 是场景中实体的数量,$N_s$ 是沿每条光线的采样点个数,$\mathbf{d}k$ 是第 $k$ 个像素点的光线,$\mathbf{x}{jk}$ 是第 $k$ 个像素其对应光线的第 $j$ 个采样点。
判别器: 我们将判别器 $D_{\phi}$ 参数化为使用Leaky ReLU作为激活函数的CNN84。
训练: 在训练过程中,我们对场景中实体的数量 $N \sim p_N$、隐向量 $\mathbf{z}s^i,\mathbf{z}_a^i \sim \mathcal{N}(0, I)$ 以及相机姿态 $\mathbf{\xi} \sim p{\xi}$ 和对象级仿射变换 $\mathbf{T}i \sim p_T$ 进行采样。在实践中,我们将 $p{\xi}$ 和 $p_T$ 分别定义为依赖于数据集相机仰角和有效对象变换的均匀分布。这种选择的动机在于,在大多数现实世界中的场景中,物体可以进行任意旋转但不会由于重力而倾斜。相比之下,观察者(此时是相机)可以自由地改变它自己的仰角去描绘场景。
我们使用非饱和GAN优化目标23和 $R_1$ 梯度惩罚85来训练我们的模型:
\[\begin{aligned} \mathcal{V}(\theta, \phi) &= \mathbb{E}_{\mathbf{z}_s^i,\mathbf{z}_a^i \sim \mathcal{N}, \mathbf{\xi} \sim p_{\xi}, \mathbf{T}_i \sim p_T}\left[ f(D_{\phi}(G_{\theta}(\{ \mathbf{z}_s^i, \mathbf{z}_a^i, \mathbf{T}_i \}_i, \mathbf{\xi}))) \right] \\ &+ \mathbb{E}_{\mathbf{I} \sim p_{\mathcal{D}}}\left[ f(-D_{\phi}(\mathbf{I})) - \lambda||\nabla D_{\phi}(\mathbf{I})||^2 \right] \end{aligned} \tag{13}\]其中 $f(t) = -\log(1 + \exp(-t))$,$\lambda = 10$, $p_{\mathcal{D}}$ 表示数据分布。
3.5 实现细节
所有对象(除去背景的 $N-1$ 个对象)的特征场 ${ h_{\theta_i}^i }{i=1}^{N-1}$ 共享它们的权重,我们将其参数化为使用ReLU激活函数的MLP网络。我们使用了8个维度为128的隐含层,1个维度为1的密度头和1个维度 $M_f = 128$ 的特征头。对于背景的特征场 $h{\theta_{N}}^N$,使用相对于普通对象MLP网络一半的层数,且其隐含层维度也减为$1/2$。位置编码中使用 $L_{\mathbf{x}} = 2 \cdot 3 \cdot 10$ 及 $L_{\mathbf{d}} = 2 \cdot 3 \cdot 4$。我们沿每条光线采样 $N_{s}=64$ 个点,并以 $16^2$ 的分辨率渲染特征图像 $I_{V}$。我们使用衰减为 $0.999$ 的指数移动平均值86作为生成器的权重。最后,将批处理大小为 $32$ 的RMSprop87作为生成器的优化器,且分别设置判别器和生成器的学习率为 $1 \times 10^{-4}$ 和 $5 \times 10^{-4}$。对于合成 $256^2$ 分辨率图片的实验,我们将 $M_f$ 设为256维并减半生成器的学习率至 $2.5 \times 10^{-4}$。
参考文献
-
Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale GAN training for high fidelity natural image synthesis. In ICLR, 2019. ↩ ↩2
-
Yunjey Choi, Min-Je Choi, Munyoung Kim, Jung-Woo Ha, Sunghun Kim, and Jaegul Choo. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In CVPR, 2018. ↩ ↩2
-
Yunjey Choi, Youngjung Uh, Jaejun Yoo, and Jung-Woo Ha. Stargan v2: Diverse image synthesis for multiple domains. In CVPR, 2020. ↩ ↩2
-
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In CVPR, 2019. ↩ ↩2 ↩3 ↩4
-
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of StyleGAN. In CVPR, 2020. ↩ ↩2 ↩3 ↩4
-
Xi Chen, Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, and Pieter Abbeel. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In NeurIPS, 2016. ↩ ↩2 ↩3
-
Anirudh Goyal, Alex Lamb, Jordan Hoffmann, Shagun Sodhani, Sergey Levine, Yoshua Bengio, and Bernhard Sch¨olkopf. Recurrent independent mechanisms. arXiv.org, 1909.10893, 2019. ↩
-
Hanock Kwak and Byoung-Tak Zhang. Generating images part by part with composite generative adversarial networks. arXiv.org, 1607.05387, 2016. ↩
-
Wonkwang Lee, Donggyun Kim, Seunghoon Hong, and Honglak Lee. High-fidelity synthesis with disentangled representation. arXiv.org, 2001.04296, 2020. ↩
-
Ming-Yu Liu, Xun Huang, Jiahui Yu, Ting-Chun Wang, and Arun Mallya. Generative adversarial networks for image and video synthesis: Algorithms and applications. arXiv.org, 2008.02793, 2020. ↩
-
Francesco Locatello, Dirk Weissenborn, Thomas Unterthiner, Aravindh Mahendran, Georg Heigold, Jakob Uszkoreit, Alexey Dosovitskiy, and Thomas Kipf. Objectcentric learning with slot attention. In NeurIPS, 2020. ↩
-
William S. Peebles, John Peebles, Jun-Yan Zhu, Alexei A. Efros, and Antonio Torralba. The hessian penalty: A weak prior for unsupervised disentanglement. In ECCV, 2020. ↩ ↩2
-
Scott Reed, Kihyuk Sohn, Yuting Zhang, and Honglak Lee. Learning to disentangle factors of variation with manifold interaction. In ICML, 2014. ↩
-
Bo Zhao, Bo Chang, Zequn Jie, and Leonid Sigal. Modular generative adversarial networks. In ECCV, 2018. ↩
-
Jun-Yan Zhu, Philipp Kr¨ahenb¨uhl, Eli Shechtman, and Alexei A. Efros. Learning a discriminative model for the perception of realism in composite images. In ICCV, 2015. ↩
-
Yoshua Bengio, Aaron C. Courville, and Pascal Vincent. Representation learning: A review and new perspectives. IEEE Trans. on Pattern Analysis and Machine Intelligence (PAMI), 35(8):1798–1828, 2013. ↩
-
Francesco Locatello, Stefan Bauer, Mario Lucic, Gunnar R¨atsch, Sylvain Gelly, Bernhard Sch¨olkopf, and Olivier Bachem. Challenging common assumptions in the unsupervised learning of disentangled representations. In ICML, 2019. ↩
-
Philipp Henzler, Niloy J Mitra, and Tobias Ritschel. Escaping plato’s cave: 3d shape from adversarial rendering. In ICCV, 2019. ↩ ↩2 ↩3
-
Thu Nguyen-Phuoc, Chuan Li, Lucas Theis, Christian Richardt, and Yong-Liang Yang. Hologan: Unsupervised learning of 3d representations from natural images. In ICCV, 2019. ↩ ↩2 ↩3
-
Thu Nguyen-Phuoc, Christian Richardt, Long Mai, YongLiang Yang, and Niloy Mitra. Blockgan: Learning 3d objectaware scene representations from unlabelled images. In NeurIPS, 2020. ↩ ↩2 ↩3
-
Yiyi Liao, Katja Schwarz, Lars Mescheder, and Andreas Geiger. Towards unsupervised learning of generative models for 3d controllable image synthesis. In CVPR, 2020. ↩ ↩2 ↩3
-
Katja Schwarz, Yiyi Liao, Michael Niemeyer, and Andreas Geiger. Graf: Generative radiance fields for 3d-aware image synthesis. In NeurIPS, 2020. ↩ ↩2 ↩3 ↩4 ↩5
-
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, and Yoshua Bengio. Generative adversarial nets. In NeurIPS, 2014. ↩ ↩2
-
Rameen Abdal, Peihao Zhu, Niloy J. Mitra, and Peter Wonka. Styleflow: Attribute-conditioned exploration of stylegan-generated images using conditional continuous normalizing flows. arXiv.org, 2008.02401, 2020. ↩
-
Edo Collins, Raja Bala, Bob Price, and Sabine S¨usstrunk. Editing in style: Uncovering the local semantics of gans. In CVPR, 2020. ↩
-
Lore Goetschalckx, Alex Andonian, Aude Oliva, and Phillip Isola. Ganalyze: Toward visual definitions of cognitive image properties. In ICCV, 2019. ↩
-
Erik H¨ark¨onen, Aaron Hertzmann, Jaakko Lehtinen, and Sylvain Paris. Ganspace: Discovering interpretable GAN controls. arXiv.org, 2004.02546, 2020. ↩
-
Ali Jahanian, Lucy Chai, and Phillip Isola. On the ”steerability” of generative adversarial networks. In ICLR, 2020. ↩
-
Yujun Shen, Jinjin Gu, Xiaoou Tang, and Bolei Zhou. Interpreting the latent space of gans for semantic face editing. In CVPR, 2020. ↩
-
Yuxuan Zhang, Wenzheng Chen, Huan Ling, Jun Gao, Yinan Zhang, Antonio Torralba, and Sanja Fidler. Image gans meet differentiable rendering for inverse graphics and interpretable 3d neural rendering. arXiv.org, 2010.09125, 2020. ↩
-
Titas Anciukevicius, Christoph H. Lampert, and Paul Henderson. Object-centric image generation with factored depths, locations, and appearances. arXiv.org, 2004.00642, 2020. ↩
-
Relja Arandjelovic and Andrew Zisserman. Object discovery with a copy-pasting GAN. arXiv.org, 1905.11369, 2019. ↩
-
Christopher P. Burgess, Lo¨ıc Matthey, Nicholas Watters, Rishabh Kabra, Irina Higgins, Matthew M Botvinick, and Alexander Lerchner. Monet: Unsupervised scene decomposition and representation. arXiv.org, 1901.11390, 2019. ↩
-
S´ebastien Ehrhardt, Oliver Groth, Aron Monszpart, Martin Engelcke, Ingmar Posner, Niloy J. Mitra, and Andrea Vedaldi. RELATE: physically plausible multi-object scene synthesis using structured latent spaces. arXiv.org, 2007.01272, 2020. ↩
-
Martin Engelcke, Adam R. Kosiorek, Oiwi Parker Jones, and Ingmar Posner. GENESIS: generative scene inference and sampling with object-centric latent representations. In ICLR, 2020. ↩
-
Klaus Greff, Rapha¨el Lopez Kaufmann, Rishabh Kabra, Nick Watters, Christopher Burgess, Daniel Zoran, Loic Matthey, Matthew Botvinick, and Alexander Lerchner. Multi-object representation learning with iterative variational inference. In ICML, 2019. ↩
-
Nanbo Li, Robert Fisher, et al. Learning object-centric representations of multi-object scenes from multiple views. In NeurIPS, 2020. ↩
-
Sjoerd van Steenkiste, Karol Kurach, J¨urgen Schmidhuber, and Sylvain Gelly. Investigating object compositionality in generative adversarial networks. Neural Networks, 2020. ↩
-
Jianwei Yang, Anitha Kannan, Dhruv Batra, and Devi Parikh. LR-GAN: layered recursive generative adversarial networks for image generation. In ICLR, 2017. ↩
-
Zhiqin Chen, Kangxue Yin, Matthew Fisher, Siddhartha Chaudhuri, and Hao Zhang. BAE-NET: branched autoencoder for shape co-segmentation. In ICCV, 2019. ↩
-
Zhiqin Chen and Hao Zhang. Learning implicit fields for generative shape modeling. In CVPR, 2019. ↩ ↩2
-
Kyle Genova, Forrester Cole, Daniel Vlasic, Aaron Sarna, William T Freeman, and Thomas Funkhouser. Learning shape templates with structured implicit functions. In ICCV, 2019. ↩
-
Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, and Andreas Geiger. Occupancy networks: Learning 3d reconstruction in function space. In CVPR, 2019. ↩ ↩2
-
Mateusz Michalkiewicz, Jhony K Pontes, Dominic Jack, Mahsa Baktashmotlagh, and Anders Eriksson. Implicit surface representations as layers in neural networks. In ICCV, 2019. ↩
-
Michael Niemeyer, Lars Mescheder, Michael Oechsle, and Andreas Geiger. Occupancy flow: 4d reconstruction by learning particle dynamics. In ICCV, 2019. ↩
-
Michael Oechsle, Lars Mescheder, Michael Niemeyer, Thilo Strauss, and Andreas Geiger. Texture fields: Learning texture representations in function space. In ICCV, 2019. ↩
-
Jeong Joon Park, Peter Florence, Julian Straub, Richard A. Newcombe, and Steven Lovegrove. Deepsdf: Learning continuous signed distance functions for shape representation. In CVPR, 2019. ↩ ↩2
-
Shunsuke Saito, Zeng Huang, Ryota Natsume, Shigeo Morishima, Angjoo Kanazawa, and Hao Li. Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization. In ICCV, 2019. ↩
-
Rohan Chabra, Jan Eric Lenssen, Eddy Ilg, Tanner Schmidt, Julian Straub, Steven Lovegrove, and Richard A. Newcombe. Deep local shapes: Learning local SDF priors for detailed 3d reconstruction. In ECCV, 2020. ↩
-
Julian Chibane, Aymen Mir, and Gerard Pons-Moll. Neural unsigned distance fields for implicit function learning. In NeurIPS, 2020. ↩
-
Chiyu Max Jiang, Avneesh Sud, Ameesh Makadia, Jingwei Huang, Matthias Nießner, and Thomas A. Funkhouser. Local implicit grid representations for 3d scenes. In CVPR, 2020. ↩
-
Songyou Peng, Michael Niemeyer, Lars Mescheder, Marc Pollefeys, and Andreas Geiger. Convolutional occupancy networks. In ECCV, 2020. ↩
-
Vincent Sitzmann, Julien N.P. Martel, Alexander W. Bergman, David B. Lindell, and Gordon Wetzstein. Implicit neural representations with periodic activation functions. In NeurIPS, 2020. ↩
-
Shichen Liu, Shunsuke Saito, Weikai Chen, and Hao Li. Learning to infer implicit surfaces without 3d supervision. In NeurIPS, 2019. ↩
-
Shaohui Liu, Yinda Zhang, Songyou Peng, Boxin Shi, Marc Pollefeys, and Zhaopeng Cui. DIST: rendering deep implicit signed distance function with differentiable sphere tracing. In CVPR, 2020. ↩
-
Michael Niemeyer, Lars Mescheder, Michael Oechsle, and Andreas Geiger. Differentiable volumetric rendering: Learning implicit 3d representations without 3d supervision. In CVPR, 2020. ↩
-
Vincent Sitzmann, Michael Zollhofer, and Gordon Wetzstein. Scene representation networks: Continuous 3dstructure-aware neural scene representations. In NeurIPS, 2019. ↩ ↩2
-
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view synthesis. In ECCV, 2020. ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
Matheus Gadelha, Subhransu Maji, and Rui Wang. 3d shape induction from 2d views of multiple objects. In Proc. of the International Conf. on 3D Vision (3DV), 2017. ↩
-
Paul Henderson and Vittorio Ferrari. Learning single-image 3d reconstruction by generative modelling of shape, pose and shading. International Journal of Computer Vision (IJCV), 2019. ↩
-
Paul Henderson and Christoph H. Lampert. Unsupervised object-centric video generation and decomposition in 3d. arXiv.org, 2007.06705, 2020. ↩
-
Paul Henderson, Vagia Tsiminaki, and Christoph H. Lampert. Leveraging 2d data to learn textured 3d mesh generation. In CVPR, 2020. ↩
-
Sebastian Lunz, Yingzhen Li, Andrew W. Fitzgibbon, and Nate Kushman. Inverse graphics GAN: learning to generate 3d shapes from unstructured 2d data. arXiv.org, 2020. ↩
-
Danilo Jimenez Rezende, S. M. Ali Eslami, Shakir Mohamed, Peter Battaglia, Max Jaderberg, and Nicolas Heess. Unsupervised learning of 3d structure from images. In NeurIPS, 2016. ↩
-
Hassan Alhaija, Siva Mustikovela, Andreas Geiger, and Carsten Rother. Geometric image synthesis. In ACCV, 2018. ↩
-
Xuelin Chen, Daniel Cohen-Or, Baoquan Chen, and Niloy J. Mitra. Neural graphics pipeline for controllable image generation. arXiv.org, 2006.10569, 2020. ↩
-
XiaolongWang and Abhinav Gupta. Generative image modeling using style and structure adversarial networks. In ECCV, 2016. ↩
-
JiajunWu, Chengkai Zhang, Tianfan Xue, Bill Freeman, and Josh Tenenbaum. Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. In NeurIPS, 2016. ↩
-
Jun-Yan Zhu, Zhoutong Zhang, Chengkai Zhang, JiajunWu, Antonio Torralba, Josh Tenenbaum, and Bill Freeman. Visual object networks: Image generation with disentangled 3d representations. In NeurIPS, 2018. ↩
-
S. M. Ali Eslami, Danilo Jimenez Rezende, Frederic Besse, Fabio Viola, Ari S. Morcos, Marta Garnelo, Avraham Ruderman, Andrei A. Rusu, Ivo Danihelka, Karol Gregor, David P. Reichert, Lars Buesing, Theophane Weber, Oriol Vinyals, Dan Rosenbaum, Neil C. Rabinowitz, Helen King, Chloe Hillier, Matt M. Botvinick, Daan Wierstra, Koray Kavukcuoglu, and Demis Hassabis. Neural scene representation and rendering. Science, 360:1204–1210, 2018. ↩
-
Hiroharu Kato, Deniz Beker, Mihai Morariu, Takahiro Ando, Toru Matsuoka, Wadim Kehl, and Adrien Gaidon. Differentiable rendering: A survey. arXiv.org, 2006.12057, 2020. ↩
-
Hiroharu Kato, Yoshitaka Ushiku, and Tatsuya Harada. Neural 3d mesh renderer. In CVPR, 2018. ↩
-
Shichen Liu, Weikai Chen, Tianye Li, and Hao Li. Soft rasterizer: Differentiable rendering for unsupervised singleview mesh reconstruction. In ICCV, 2019. ↩
-
Thu Nguyen-Phuoc, Chuan Li, Stephen Balaban, and YongLiang Yang. Rendernet: A deep convolutional network for differentiable rendering from 3d shapes. In NeurIPS, 2018. ↩
-
Vincent Sitzmann, Justus Thies, Felix Heide, Matthias Nießner, Gordon Wetzstein, and Michael Zollh¨ofer. Deepvoxels: Learning persistent 3d feature embeddings. In CVPR, 2019. ↩
-
Ayush Tewari, Ohad Fried, Justus Thies, Vincent Sitzmann, Stephen Lombardi, Kalyan Sunkavalli, Ricardo MartinBrualla, Tomas Simon, Jason M. Saragih, Matthias Nießner, Rohit Pandey, Sean Ryan Fanello, Gordon Wetzstein, JunYan Zhu, Christian Theobalt, Maneesh Agrawala, Eli Shechtman, Dan B. Goldman, and Michael Zollhofer. State ¨ of the art on neural rendering. Computer Graphics Forum, 2020. ↩
-
Justus Thies, Michael Zollhofer, and Matthias Nießner. Deferred neural rendering: image synthesis using neural textures. ACM Trans. on Graphics, 2019. ↩
-
Matthew Tancik, Pratul P. Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T. Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains. In NeurIPS, 2020. ↩
-
Robert A. Drebin, Loren C. Carpenter, and Pat Hanrahan. Volume rendering. In ACM Trans. on Graphics, 1988. ↩
-
Lingjie Liu, Jiatao Gu, Kyaw Zaw Lin, Tat-Seng Chua, and Christian Theobalt. Neural sparse voxel fields. In NeurIPS, 2020. ↩
-
Ricardo Martin-Brualla, Noha Radwan, Mehdi S. M. Sajjadi, Jonathan T. Barron, Alexey Dosovitskiy, and Daniel Duckworth. Nerf in the wild: Neural radiance fields for unconstrained photo collections. arXiv.org, 2008.02268, 2020. ↩
-
Andrew L. Maas, Awni Y. Hannun, and Andrew Y. Ng. Rectifier nonlinearities improve neural network acoustic models. In ICML Workshops, 2013. ↩
-
Bing Xu, Naiyan Wang, Tianqi Chen, and Mu Li. Empirical evaluation of rectified activations in convolutional network. arXiv.org, 1505.00853, 2015. ↩
-
Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. In ICLR, 2016. ↩
-
Lars Mescheder, Andreas Geiger, and Sebastian Nowozin. Which training methods for gans do actually converge? In ICML, 2018. ↩
-
Yasin Yazici, Chuan-Sheng Foo, Stefan Winkler, Kim-Hui Yap, Georgios Piliouras, and Vijay Chandrasekhar. The unusual effectiveness of averaging in GAN training. In ICLR, 2019. ↩
-
T. Tieleman and G. Hinton. Lecture 6.5—RmsProp: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning, 2012. ↩