Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
「Paper」Swin Transformer:Hierarchical Vision Transformer using Shifted Windows
从ViT引出的计算资源问题
在ViT的基本思想中,由于Transformer对过长序列的处理效果不好,而图像像素又是很密集的,通常是使用patch的方式将图片化作数量更少的patch后当作token序列交给Transformer进行处理。但是,ViT是在整张图片的所有patch上计算Self-Attention以获得全局相关性(所有token之间的互相关),这样就会引入计算资源的消耗问题:
问题1
- ViT不适用于密集型预测(比如目标检测与语义分割)和表示高分辨率图像等需要处理巨量token的任务
如果将局部相邻的patch视作1个小窗口,在每个小窗口里对各个patch计算Self-Attention,这样会大大降低所需的计算资源,但同时也会导致另一个问题:
问题2
- 由于窗口之间没有重叠,窗口内的像素无法捕捉到其他不同窗口内的其他像素的相关性,变成了孤立自注意力,失去了全局建模的能力
对于问题1,下面具体分析ViT中的全局自注意力和基于不重叠窗口的局部自注意力间的计算资源消耗
计算复杂度对比分析
自注意力通常采用的注意力评分函数(Attention Scoring Function)是缩放点积注意力(Scaled Dot-product Attention),每个注意力头的计算过程如公式(1)所示,其中$d$为query/key的特征维度:
\[\textrm{Attention}(Q,K,V) = \textrm{SoftMax}(QK^\textrm{T}/\sqrt{d})V \tag{1}\]注意,下面的计算复杂度分析中忽略了SoftMax的计算消耗
首先,分析全局注意力与局部窗口注意力二者的计算复杂度,多头自注意力的计算流程图如图1所示:
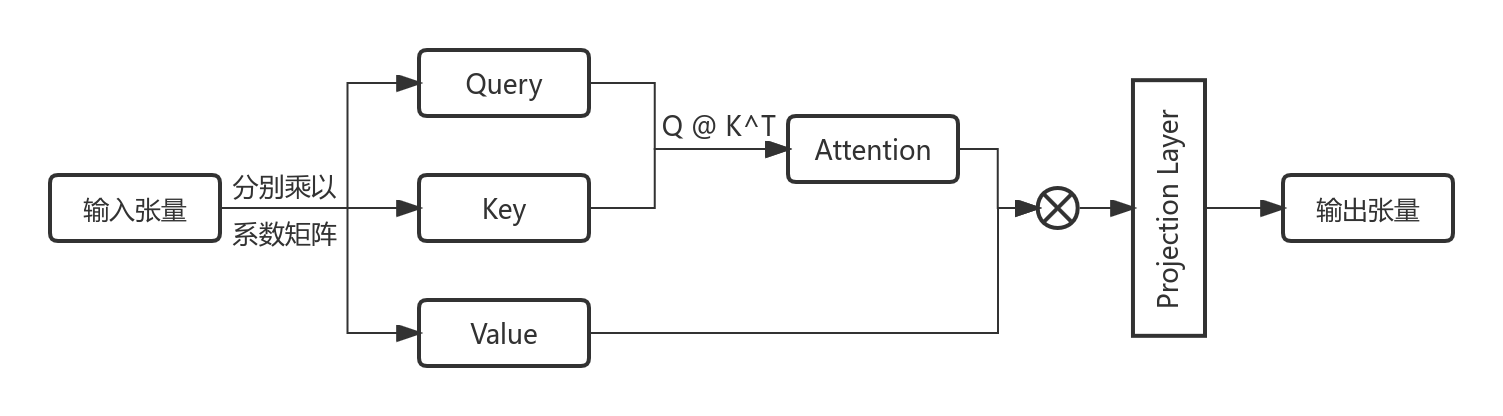
上图中,输入张量为图片的Patch Embedding张量,分别乘以3个系数矩阵后便可得到与输入张量具有相同形状的$QKV$(查询-键-值),尔后$Q$与$K^\textrm{T}$进行矩阵乘法以得到权重矩阵Attention,将其与值矩阵$V$相乘,即用权重矩阵Attention对$V$进行加权操作。由于是多头注意力,要将各个注意力头的输出合并后做投影操作投射到与输入张量相同的特征维度上
全局自注意力
一张图片经过Patch Embedding后共形成$h \times w$个patch,则拉直后的token序列长度为$hw$且每个token的特征维度为$C$,意味着输入张量的形状为$hw \times C$。在这些patch上执行全局多头自注意力(Multihead Self-Attention, MSA)计算的复杂度如公式(2)所示,具体复杂度计算流程如图2所示:
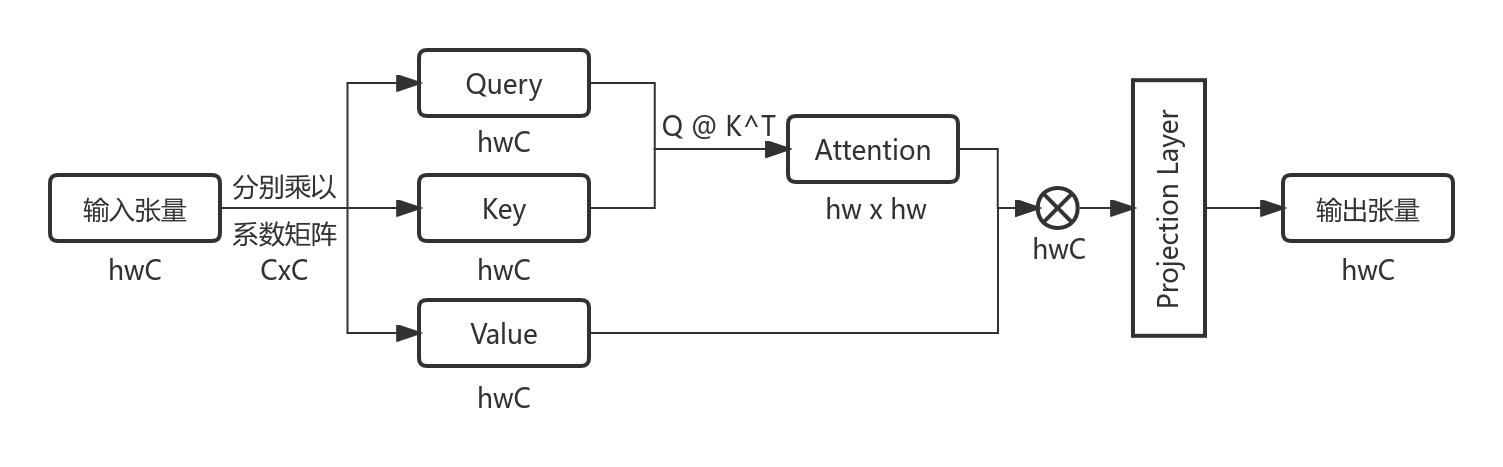
上图中,输入张量到$QKV$的变换消耗了$3hwC$(大小为$hw \times C$的矩阵和$C \times C$的矩阵相乘需要$hwC$次计算),接着$Q$与$K^\textrm{T}$(形状为$C \times hw$)相乘消耗了$(hw)^2C$,Attention与$V$的计算消耗亦为$(hw)^2C$,最后投影操作将大小为$hwC$的加权张量投影为相同大小的输出张量上,这一步也消耗$hwC$。合并后即可得到公式(2):
\[\Omega(\textrm{MSA}) = 4hwC^2 + 2(hw)^2C \tag{2}\]基于不重叠窗口的局部自注意力
假设每个窗口包含$M \times M$个patch(即图1中的Layer l每个窗口的宽高),在每个窗口中计算自注意力(Window based Multihead Self-Attention, W-MSA)时可以调用全局自注意力的复杂度公式(2),这里序列长度不是$h \times w$而是窗口中的patch个数$M \times M$,单个小窗口将消耗:
\[\Omega(\textrm{MSA-per-window}) = 4M^{2}C^{2}+2M^{4}C \tag{3}\]而一张图片一共具有$\frac{h}{M} \times \frac{w}{M} = \frac{hw}{M^2}$个小窗口,乘以上式即可得到整张图片的计算复杂度,如公式(4)所示
\[\Omega(\textrm{W-MSA}) = 4hwC^2 + 2M^2hwC \tag{4}\]比较
对比公式(1)(3),由于小窗口的固定宽高$M$通常远小于图片被分成patch后的宽高$h$和$w$,其复杂度差异其实很大
\[\Omega(\textrm{MSA}) - \Omega(\textrm) = 2(hw - M^2)hwC \tag{5}\]虽然这样能够大大节省计算资源,但是由于窗口和窗口之间没有联系,其问题也是显而易见的
Shifted Window based Self-Attention
Swin-Transformer最重要的思想便在于解决上述问题
Swin 为 Shifted window 即移位窗口的意思。对于问题2,为了捕捉相邻窗口间patch的相关性,Swin Transformer采用移位窗口的方法,如图3所示:
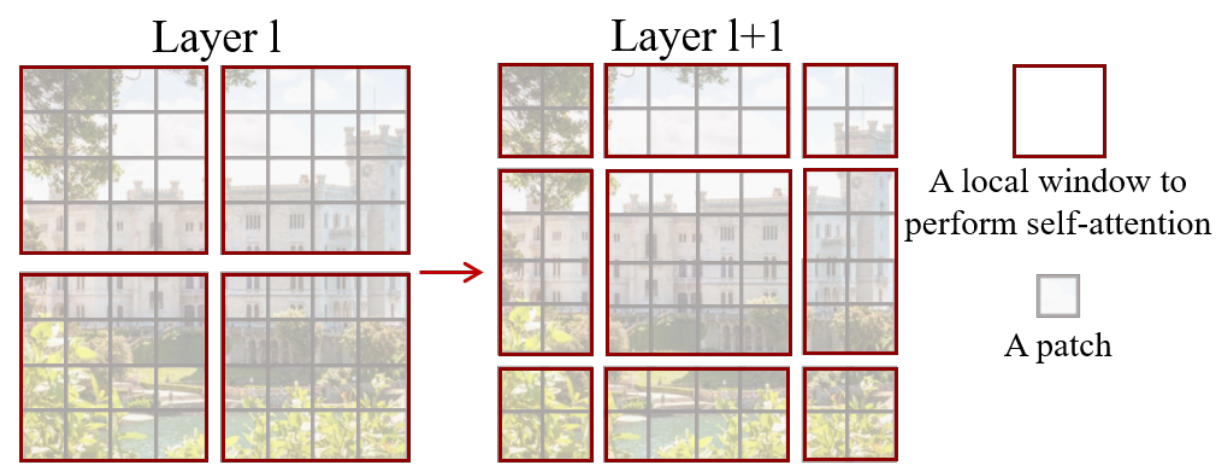
上图清晰地展示了如何进行窗口的移位:将原始的窗口整体向右下角移动2个patch,这样原先的4个窗口就会形成大小不一的9个窗口,这样在新的窗口里进行自注意力计算时就可以为之前不在同一窗口的patch之间提供联系,即Cross-Window Connection
图片的patch在模型中前向传播到更深层时,每一个patch的感受野已经很大了,这种移位窗口方法的自注意力计算就变相的等于一个全局自注意力操作的效果,较为节省计算资源且效果相当
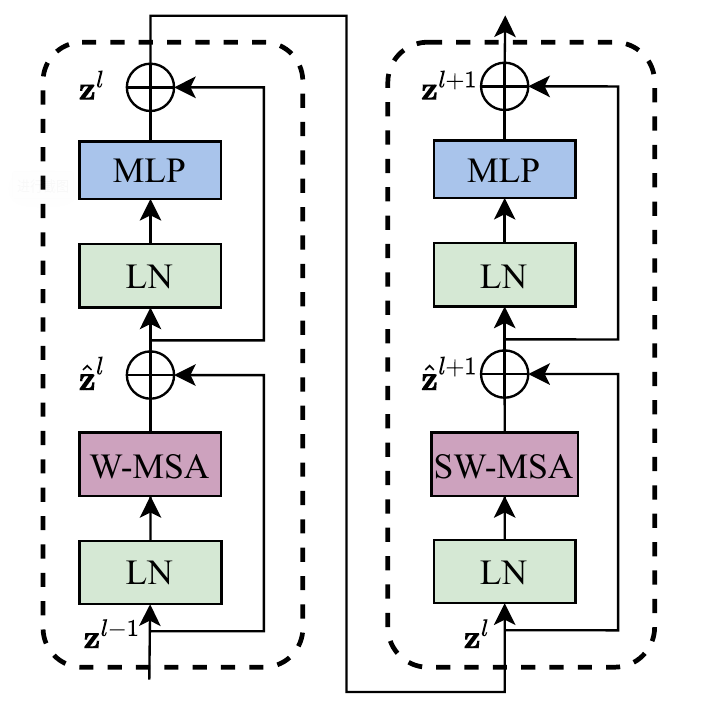
Swin-Transformer每个Stage的Transformer块都是成对出现的,在第1个块中进行$\textrm{W-MSA}$计算,在第2个块中对前一步的窗口执行移位并计算$\textrm{SW-MSA}$,流程如图4所示:
Efficient batch computation for shifted configuration
虽然移位窗口的方法效果不错,但是窗口数量从4增加到了9,且每个窗口的大小不一,如果想进行批量自注意力计算的话会碰到问题。论文作者提出了一种巧妙的解决方法用以加速移位窗口的批量计算,如图5所示:
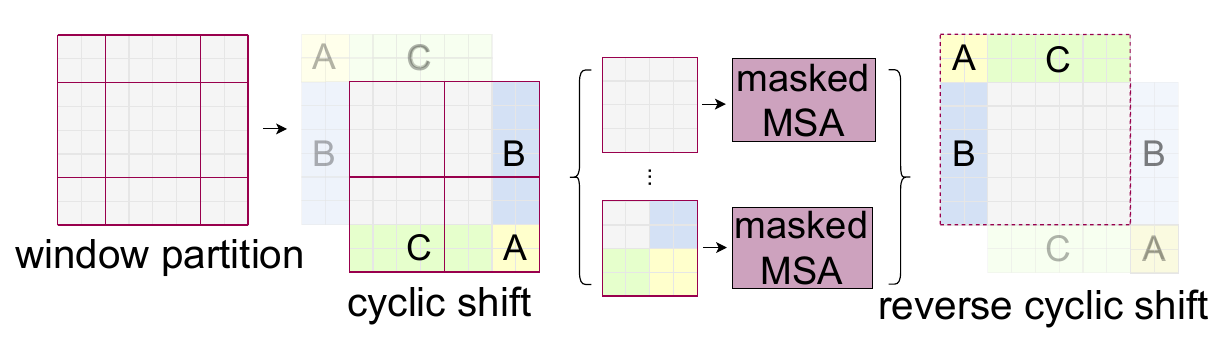
上图中,将移位窗口中的左上(A)、正左(B)、正上(C)通过循环移位分别移动到原来的9个窗口的右下、正右、正下,这样原先的9个窗口又会被拼成最原始的4个窗口的形式
但是,由于原9个窗口内部需要做自注意力计算,移动后并不能直接在4个新窗口内直接执行计算,因为patch被移动后会丢失其相邻的语义信息。作者提出了遮罩多头注意力的计算方法,使得新窗口内不相关的patch间的注意力权重被降到极低,从而达到”$\textrm{Masked}$”的效果,这样仅通过一次前向传播便可计算当前整个小批量的移位窗口自注意力
根据官方代码库的Issue#38,作者给出了掩码的可视化图片,如图6所示:
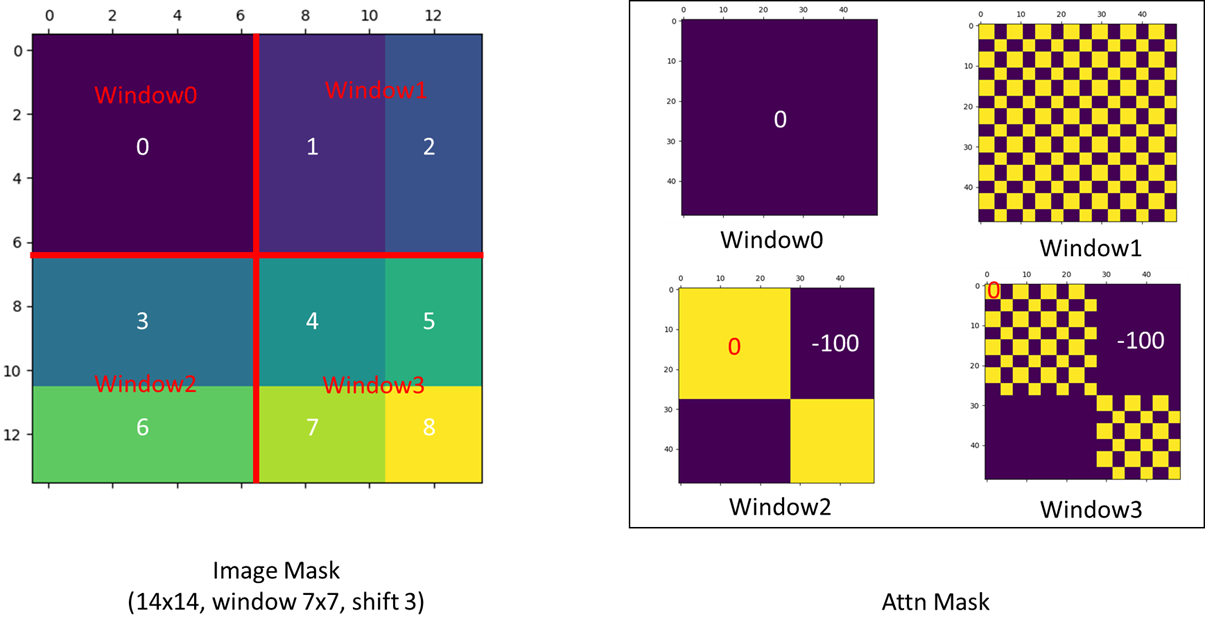
Window 0
窗口0中的patch本就是相邻的,不需要mask
Window 2
窗口2中,由于各patch要被从左到右、从上到下的顺序拉直为token序列,当其中的patch被拉直后,序号为3的子窗口patch在序号为6的子窗口patch的前部,如图7所示:
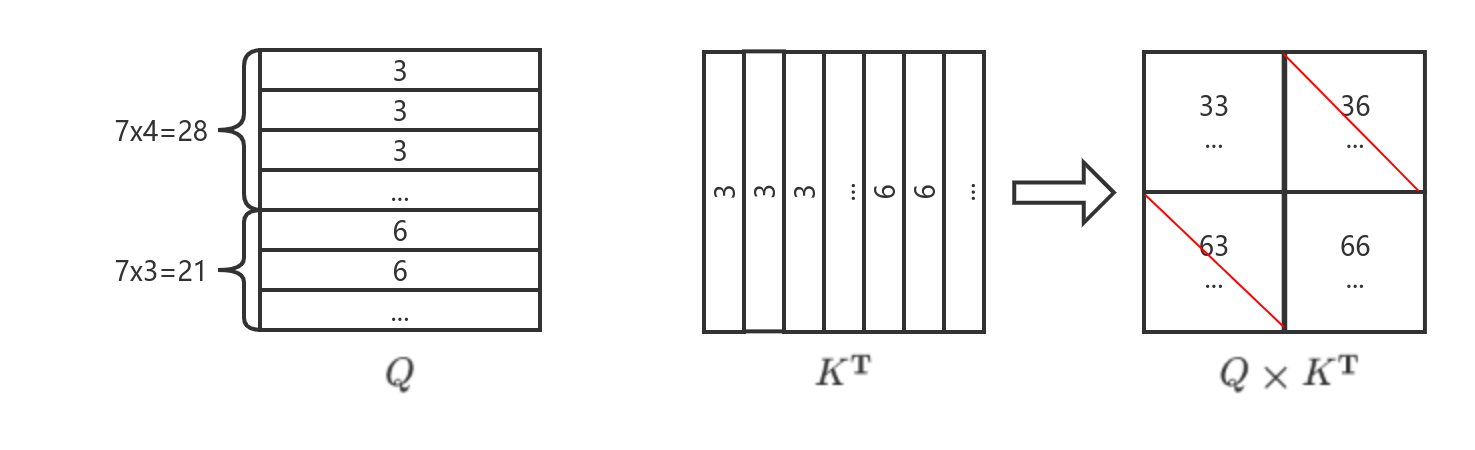
注意这里的$hw$为$14 \times 14$,窗口大小$M=7$,移位的大小为$3$,则3号子窗口大小为$7 \times 4$包含28个token,则6号子窗口包含21个token。这样计算自注意力的时候,由于$K$被转置,执行$Q$与$K^\textrm{T}$的矩阵乘法后可以发现只有左上和右下的对角块矩阵是原先的相邻patch进行自注意力计算,而左下和右上进行的是无效计算。因此针对Window2可以采用图6中的Attention Mask与$QK^\textrm{T}$执行元素加,将不相关区域的权重值直接减去100,这样在SoftMax时会变换为趋于0的值,最终得到的注意力矩阵就不含不相邻patch的注意力分数
Window 1
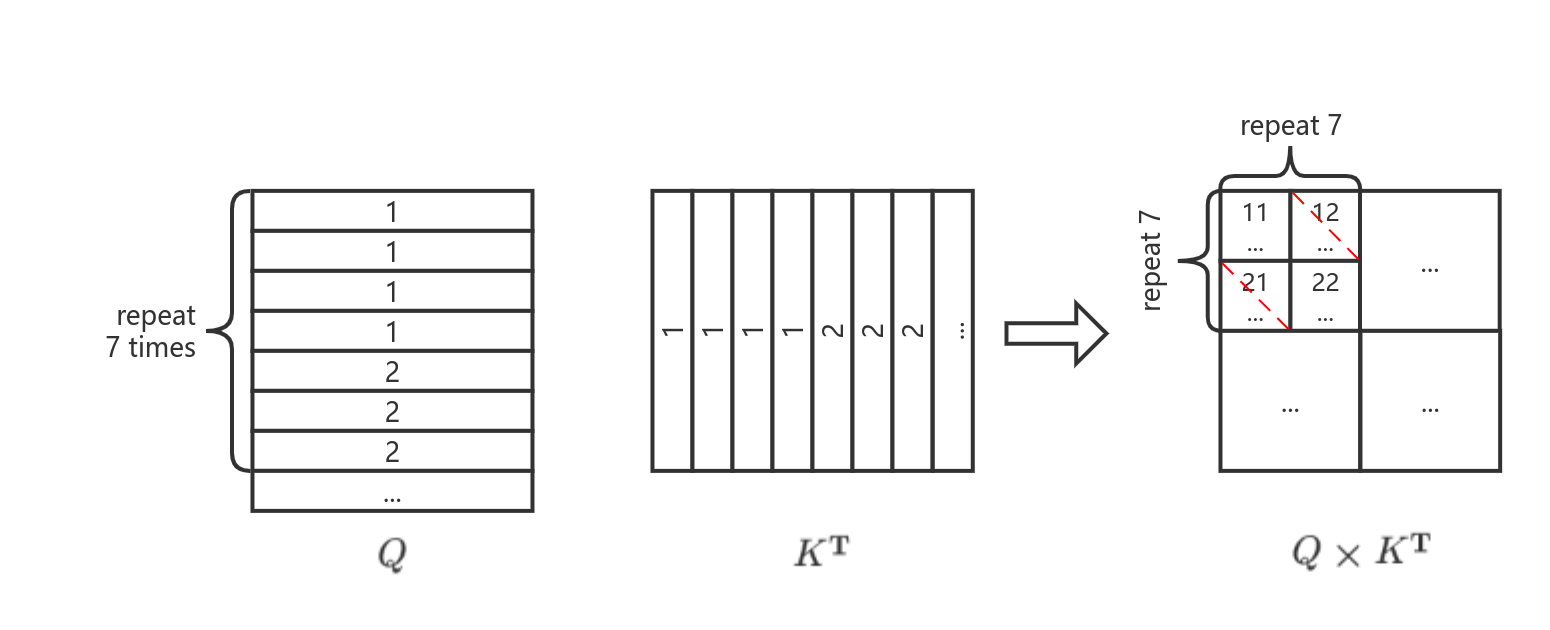
窗口1类似窗口2,不过在token序列的拉直过程中,子窗口1和子窗口2的patch是交替出现的,因此其对应的Attention Mask也是如棋盘格般的形状
Window 3
窗口3中包含4个不相关子窗口的自注意力计算,类比前面的推导很容易得出Attention Mask的形状
Relative position bias
在计算自注意力时,作者还在缩放点积注意力函数中添加了相对位置偏置(relative postion bias),如公式(6)所示:
\[\textrm{Attention}(Q,K,V) = \textrm{SoftMax}(QK^\textrm{T}/\sqrt{d}+B)V \tag{6}\]其中$Q,K,V \in \mathbb{R}^{M^2 \times d}$,偏置$B \in \mathbb{R}^{M^2 \times M^2}$以匹配$QK^\textrm{T}$的形状
在相对位置编码中,如果窗口大小为$M$,在每个轴上(图片是二维的所以有行列2个轴)刻画每个位置上的patch与其他patch的相对距离时,其取值显然落在区间$[-M+1, M-1]$内,即一共$2M-1$种取值
作者添加了可学习的相对位置偏置参数$\hat{B} \in \mathbb{R}^{(2M-1) \times (2M-1)}$,这样尺寸更大的$B$中的值可以从$\hat{B}$中得到
具体取值过程见以下节选自官方代码仓库的WindowAttention类,添加了我自己理解的注释
#! in models/swin_transformer.py
class WindowAttention(nn.Module):
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None,
attn_drop=0., proj_drop=0.)
...
self.window_size = window_size # Tuple(M, M)
# 定义相对位置偏置的参数表,这里是将y轴与x轴的相对位置偏置一起拉直为第0维,以方便后续取值
# shape = [(2M-1) * (2M-1), nH]
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads))
# 使用截断正态分布初始化该参数表
nn.init.trunc_normal_(relative_position_bias_table, std=.02)
# 为窗口内的每个token计算成对出现的相对位置索引
# 首先得到每个token对应的xy坐标索引
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
# 利用torch.meshgrid生成2个M*M的坐标索引矩阵,第1个为y坐标矩阵,第2个为x坐标矩阵
# 将二者在dim=0堆叠,此时shape=(2, M, M)
coords = torch.stack(torch.meshgrid([coords_h, coords_w]))
# 从dim=1开始拉直,shape=(2, M*M)
# 这样dim=0上的2个张量分别对应当前窗口内所有patch形成的token序列的y坐标序列、x坐标序列
coords_flatten = torch.flatten(coords, start_dim=1)
# 利用广播机制计算每个patch相对于其他patch位置的坐标偏移(分别沿着y轴与x轴)
# shape=(2, M*M, M*M)
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
# 把dim=0调到最后一维,shape=(M*M, M*M, 2)
relative_coords = relative_coords.permute(1, 2, 0).contiguous()
# 分别对y轴相对位置和x轴相对位置执行偏移加上M-1,将取值区间从[-M+1, M-1]变换到[0, 2M-2]
relative_coords[:, :, 0] += self.window_size[0] - 1
relative_coords[:, :, 1] += self.window_size[1] - 1
# 将y轴相对坐标乘以2M-1将取值区间变换到[0, (2M-2)*(2M-1)]
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
# 将每个patch的y轴相对位置与x轴相对位置加到一起,shape=(M*M, M*M)
# 索引取值区间为[0, (2M-2)*(2M-1)] + [0, 2M-2] => [0, 2M(2M-2)]
# 即满足参数表的索引取值范围 0 <= idx < (2M-1)^2-1 = 2M(2M-2)
relative_position_index = relative_coords.sum(dim=-1)
# 标记为不随训练更新的张量
self.register_buffer("relative_position_index", relative_position_index)
...
def forward(self, x, mask=None):
...
# 缩短代码行长度,拎出M值
M = self.window_size[0] # = self.window_size[1]
# 注意相对位置偏置表的形状为[(2M-1) * (2M-1), nH]
# 将前面得到的相对位置索引(形状为[M^2, M^2])拉直为1维后,将其值作为索引去取偏置表中的值
# 每个值张量的形状都是(1, nH),一共取得M^4个偏置值,shape=(M^4, nH)
# 尔后重新reshape为(M^2, M^2, nH)以得到注意力头使用的偏置参数矩阵B
relative_position_bias = self.relative_position_bias_table[
self.relative_position_index.view(-1)].view(M * M, M * M, -1)
# 把num_heads所在维度调换到第0维,完成了B从\hat{B}中进行取值的过程,得到每个注意力头的偏置B
# shape=(nH, M*M, M*M)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
...