分布式系统负载均衡与限流算法
成熟的线上业务处于各种原因考量,多是分布式系统,每个服务集群有很多实例,上游请求调用服务对外暴露的接口时,需要通过负载均衡合理地将请求分配到不同实例上进行处理,同时分布式限流中间件要控制传入整个服务集群的请求数量与频率,防止集群依赖的资源(比如其他服务、数据库等)被大量请求涌入导致服务雪崩
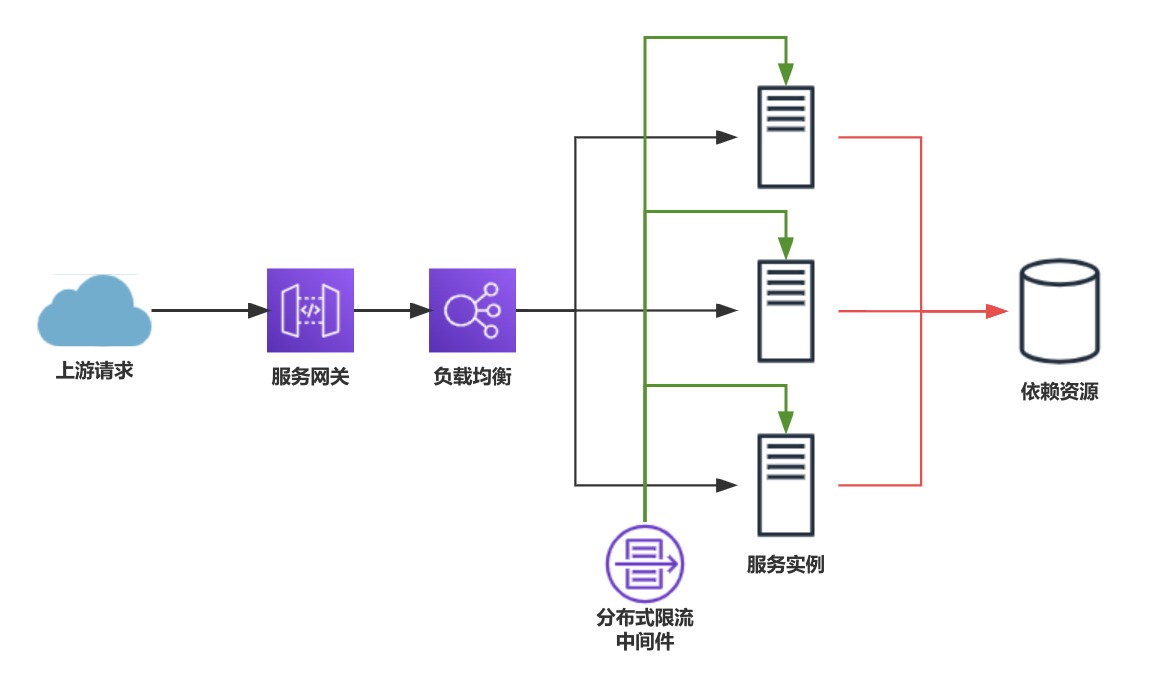
负载均衡算法
轮询法 Round Robin
将请求按顺序轮流分配到服务器上,它平等地对待服务集群的每一个实例,不关注实例实际的连接数和当前系统负载
加权轮询法 Weighted Round Robin
不同的实例其机器配置和当前系统负载并不相同,导致它们的抗压能力也不同。加权轮询法的思想就是给配置高、负载低的实例分配更高的权重,配置低、负载高的实例分配较低的权重,在轮询时按照权重将请求顺序地分配到服务实例上,能够很好缓解资源利用率不均衡的问题
“顺序”的含义是指,本质还是生成的一张轮询列表,但是服务实例按照其权重连续出现多次,以Nginx配置带权轮询为例:
upstream backend {
ip_hash;
server 192.168.1.232 weight=4;
server 192.168.1.233 weight=3;
server 192.168.1.234 weight=1;
}
这样的话生成的带权轮询列表就是 A,A,A,A,B,B,B,C,这样的话按照普通轮询方法每一个请求就分配给轮询列表中的下一个实例即可,但是这样也会带来一个问题:权重大的服务实例一次性要接收大量请求
实际上Nginx中实现的带权轮询是平滑的,通过调整权重相同的重复实例在轮询列表中的位置,可以缓解上述问题,比如平滑后的带权轮询列表: A,A,B,A,B,A,B,C
随机法
通过系统的随机算法,从服务实例列表中随机选取一台服务器进行分配,由林德伯格大数统计理论,随着客户端请求被分配到不同服务端的次数增多,其实际效果也越来越接近轮询法中的调用量平均分配
加权随机法
与加权轮询法的思想类似,根据配置和负载分配不同的权重,但是请求是按照加权后随机分配,而不是像加权轮询法那样按照加权后的列表顺序分配的
同加权轮询法一样首先需要生成一张轮询列表,其中的服务实例按照其权重连续出现多次,计算权重总和后,利用随机数生成一个落在0~权重总和区间的随机权重,根据随机权重所在的区间选择对应服务实例即可
源地址哈希法
根据客户端的IP地址,通过哈希函数计算其哈希值,并使用除留余数法,对服务器列表大小取模,便可获得该客户端请求待分配的服务实例序号,这样的话当服务实例列表不变(没有实例下线或者新实例上线)时,同一源IP地址的请求每次都会映射到同一个服务实例处理
如果实例变动较为频繁,每次变动后都要更新实例列表,所以就引进了一致性哈希算法,对2^32取模(形似一个哈希环),服务实例也是通过IP地址等取模安置在哈希环上,将请求的源IP地址对应的哈希取模后分配到最接近的服务实例上
当然这又会引出个问题,那就是服务实例的倾斜问题,当大部分服务实例密集地分配在哈希环的某段位置,一致性哈希算法的效果就会大打折扣,可以通过引入虚拟节点映射到实际服务实例的方式,均匀地分段整个哈希环
最小连接数法
由于不同服务实例的配置不尽相同,且每个请求处理的时间有快有慢,最小连接数法是根据当前后端服务的连接情况,动态选取当前积压连接数最少的一台服务器以处理当前请求,这样能够尽可能地提高后端服务的利用率,将请求合理地分流到每一台服务器
限流算法
在云原生的当下,分布式、微服务等概念的兴起,促使了服务间的API调用激增。由于API接口无法控制调用方的行为,当瞬时请求量激增时就会导致接口占据过多服务器资源,使得其他请求响应速度降低或者超时,甚至导致服务器宕机
限流(RateLimiting)是指对应用服务的请求进行限制,当请求频率超过限制时,对超过限制的请求做出处理,比如快速失败、排队等待或者直接丢弃等
限流在如今的云原生场景中是必需的,用以应对公开的服务接口或者内部服务之间的:
-
热点业务带来的突发请求高峰
-
调用方BUG导致的突发请求
-
恶意洪泛的攻击请求
固定窗口计数器
固定窗口计数器是最简单的限流算法,其思想如下:
-
将时间轴划分为多个窗口
-
每个窗口内每有一次请求就将当前窗口的计数器+1
-
当计数器数值超过了限制的请求数量上限,后续的请求都被直接丢弃
-
时间流动到下个窗口后,重置计数器
这种限流算法简单粗暴,但其实问题也很明显:如果两个紧挨着的时间窗口,前一个窗口的后半部分和后一个窗口的前半部分都被请求塞满,从整体上看就像相同窗口时间内请求数量达到了限制时间的两倍
滑动窗口计数器
滑动窗口计数器是对固定窗口计数器的改进,基于经典的滑动窗口概念:
-
将时间轴划分为多个时间片,时间窗口的大小固定为$x$个时间片
-
每个时间片每有一次请求将当前时间片的计数器+1
-
每经过一个时间片的时间,便抛弃最久的一个时间片,并纳入下一个时间片,即窗口沿着时间轴滑动
-
如果当前窗口内所有时间片的计数器总和超过了限制的请求数量上限,丢弃后续到来的请求
滑动窗口计数器算法避免了固定窗口计数器中可能出现的双倍突发请求情况,但是随着划分时间片的粒度增加,计数器数量所占空间也越大,统计请求总数的频率也越高
漏桶
计数器算法需要限流中间件统计时间段内的请求总数,主动统计显然会消耗些许性能
漏桶算法的概念是通过被动方式限制请求速率,其思想如下:
-
将每个请求视作“水滴”,存入“漏桶”中
-
漏桶以固定速率向外“漏出”请求,交付服务实例进行处理,当漏桶为空则停止漏水
-
如果漏桶已满,则多余的水滴请求就像溢出了一般,直接被丢弃
根据漏桶算法的特点,一般使用FIFO的队列实现该算法,对于服务的请求依次进入队列,服务实例按照固定的速率从队列中取出请求并执行,其余请求放在队列中排队,超出队列容量后直接丢弃后续到达的请求
其缺点也很明显:当服务集群的实例较为空闲时,短时间内出现大量突发请求,每个请求也都得在队列中等待一段时间才能被处理,而不是一次性喂饱
令牌桶
令牌桶算法针对漏桶算法的缺点进行了改进:
-
令牌桶中存储的是“通关”令牌,令牌以固定速率生成
-
生成的令牌存于令牌桶中,如果令牌桶容量已满则丢弃多余令牌
-
每个请求到达时,会尝试从令牌桶中取出一个令牌,拥有令牌的请求可以通行
-
当令牌桶为空时,请求便获取不到令牌,直接丢弃没有令牌的请求
令牌桶算法综合了漏桶的优点,既能够将所有的请求平均分布到时间区间中,又能够让服务实例在遇到其可承受范围内的突发请求时能够快速吃满,迅速解决问题
令牌桶生成令牌的速率也可以动态调整,主动应对热点高峰,相当于提高了能够处理的请求上限